- Analyze the performance of neural networks
- Find low-performing slices of data
- Surface labeling mistakes
- Identify high-impact data to label in order to model performance
Supported attributes for search and filter
Below are the attributes you can search and filter by in the Model product.| Attribute | Description | Examples |
|---|---|---|
| Annotation | Find data rows with labels that contain or do not have certain counts of annotations | Show image assets where X annotation was used at least N times. |
| Prediction | Predictions uploaded to the model run | Show text assets where the model predicted X at least N times. |
| Data row | Filter on any data row identifiers (e.g., global key, data row ID, and external ID) | Show all image assets where the global key does not contain X. |
| Label | Find data rows by the ID of associated labels. | Show all text assets where a label ID contains X. |
| Dataset | Find data rows that belong to a particular dataset. | Show all image assets uploaded to dataset X. |
| Project | Find data rows that are associated with a specific labeling project | Show all text assets uploaded to project X. |
| Metrics | Model run metrics (auto-generated and custom) | Show image assets with specific values for precision, recall, intersection over union, etc. Filter on aggregated or per prediction metrics |
| Metadata | Find data rows that contain a certain metadata field and/or value | Show text assets that were captured between two datetimes |
Filters
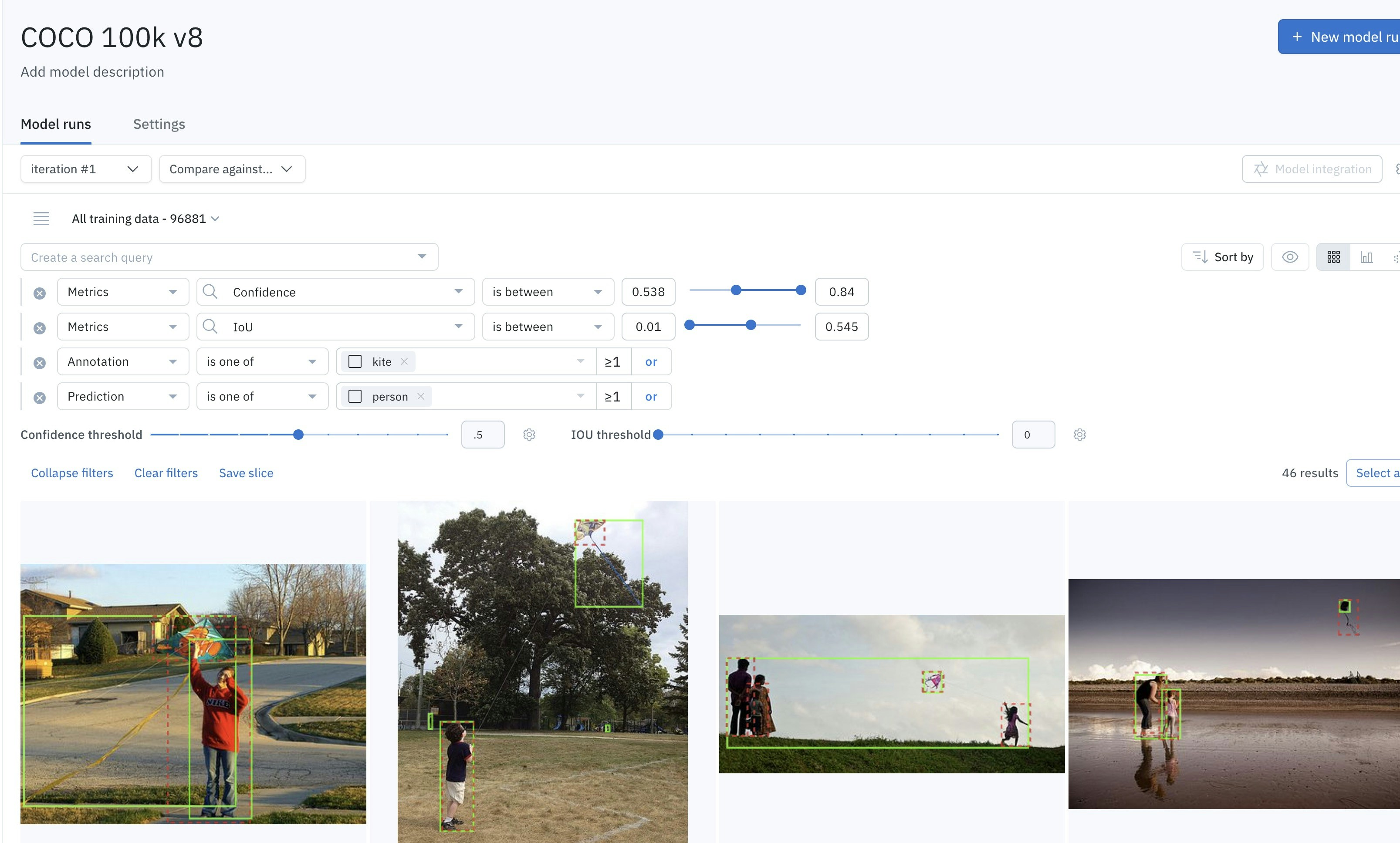
You can think of filters as pyramids with layers of logical sequence. Each filter condition is a layer that limits the data rows in the view. You can think of each layer as an “AND” condition in a logical construct. Within a layer, you can add additional match conditions (“OR” conditions). The final results count reflects the data rows that match all currently specified conditions. The following screenshot shows several AND conditions, including:- Metrics where confidence is between 0.538 and 0.84.
- Metrics where IoU is between 0.01 and 0.545.
- Data rows with an annotation of
kiteor a prediction ofperson.
Filter on custom metrics per prediction basis
You can upload custom metrics to model runs and then them in model view filters. For help uploading custom metrics, see Model Diagnostics - Custom Metrics demo. You can filter predictions by auto-generated metrics, by custom metrics, or both. This lets you create a unique view, such as filtering by a specific custom metric and then refining that with values in specific ranges, as shown in the following image. You can also combine such filters with other filters to create even more tailored views. To do this, select Metrics as your filter type and then select per prediction. Next, select the specific feature you want to use to filter your model view. Next, add additional filter conditions to create the specific view you need.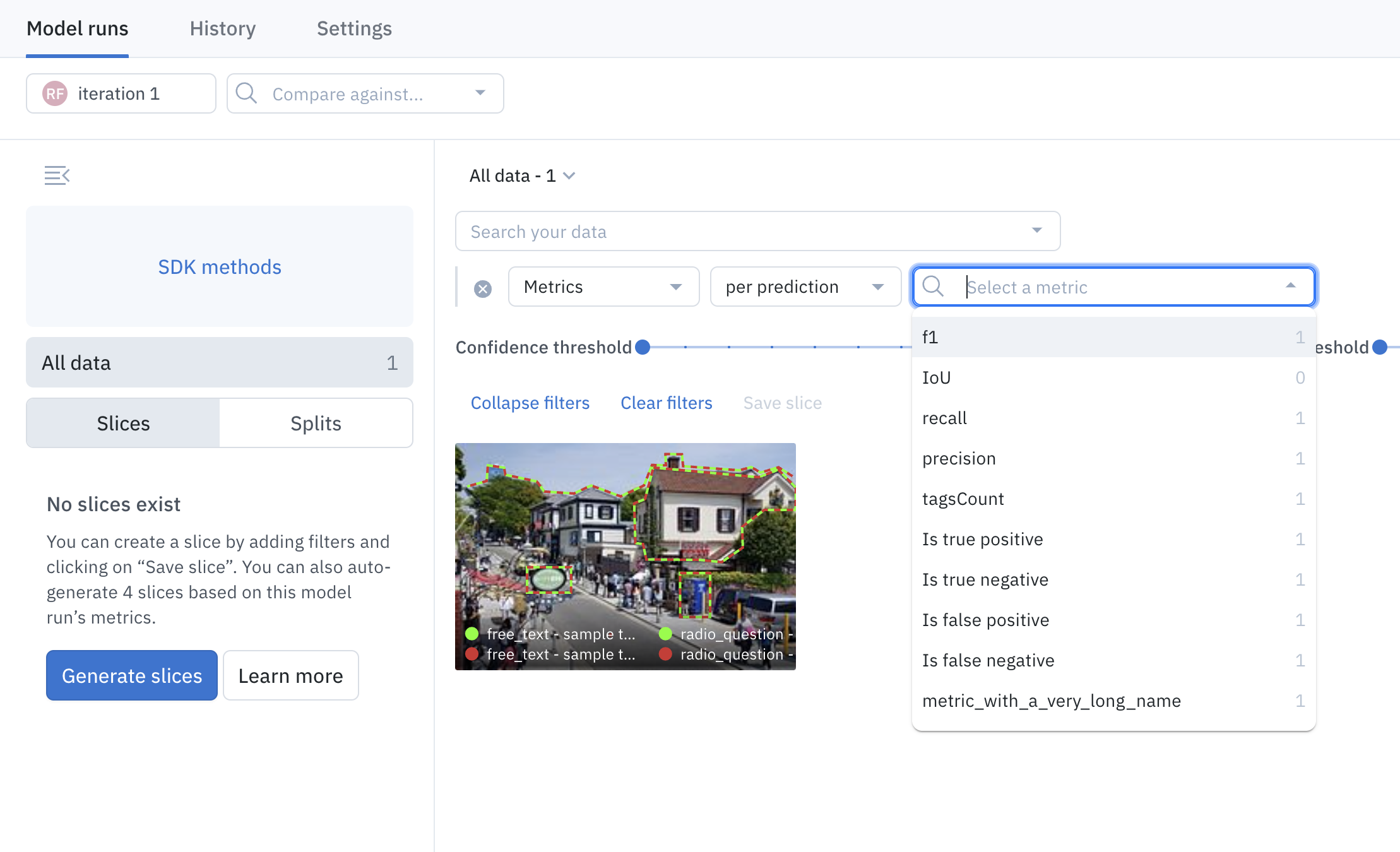
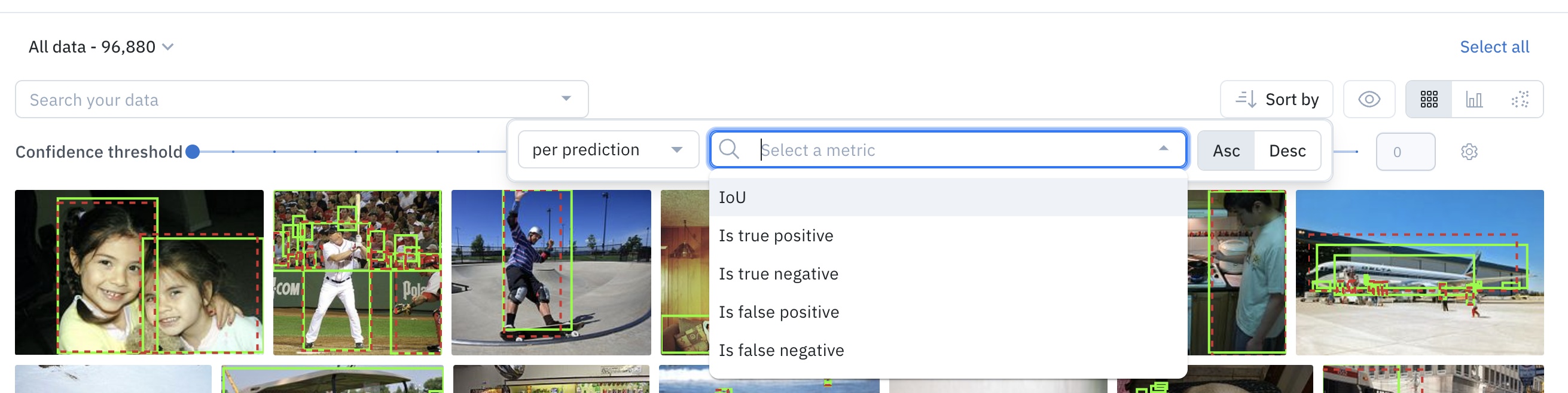
Sort by
You can sort data on any combination of auto-generated metrics and/or custom metrics. To do so, click on Sort by, then pick the desired metric and decide if the sorting should be in ascending order (Asc) or descending order (Desc). You can pick metric filtering per prediction for sorting a particular metric or aggregated for sorting by the arithmetic mean of the metric.