Specifications
File format: JSON in our conversation format Encoding: UTF-8 (Note: The Editor does not process any special character sequences like HTML Entities, Unicode Escape Sequence, or colon emoji aliases.) Import methods:- IAM Delegated Access
- Signed URLs (
httpsURLs only)
| Parameter | Required | Description |
|---|---|---|
row_data | Yes | https path to a cloud-hosted conversational text JSON file. See the section below for details on our conversation format. For IAM Delegated Access, this URL must be in virtual-hosted-style format. For older regions, your S3 bucket may be in https://<bucket-name>.s3.<region>.amazonaws.com/<key> format. If your object URLs are formatted this way, make sure they are in the virtual-hosted-style format before importing. |
global_key | No | Unique user-generated file name or ID for the file. Global keys are enforced to be unique in your org. Data rows will not be imported if their global keys are duplicated to existing data rows. |
media_type | No | "CONVERSATIONAL" (optional media type to provide better validation and error messaging) |
metadata_fields | No | See Metadata. |
Import format
[
{
"row_data": "https://storage.googleapis.com/labelbox-datasets/conversational-sample-data/pairwise_shopping_1.json",
"global_key": "global_key_1"
},
{
"row_data": "https://storage.googleapis.com/labelbox-datasets/conversational-sample-data/pairwise_shopping_2.json",
"global_key": "global_key_2"
},
{
"row_data": "https://storage.googleapis.com/labelbox-datasets/conversational-sample-data/pairwise_shopping_3.json",
"global_key": "global_key_3"
}
]
Python example
# Generate dummy global keys
global_key_1 = str(uuid.uuid4())
global_key_2 = str(uuid.uuid4())
global_key_3 = str(uuid.uuid4())
# Create a dataset
dataset = client.create_dataset(
name="pairwise_demo_"+str(uuid.uuid4()),
iam_integration=None
)
# Upload data rows
task = dataset.create_data_rows([
{
"row_data": "https://storage.googleapis.com/labelbox-datasets/conversational-sample-data/pairwise_shopping_1.json",
"global_key": global_key_1
},
{
"row_data": "https://storage.googleapis.com/labelbox-datasets/conversational-sample-data/pairwise_shopping_2.json",
"global_key": global_key_2
},
{
"row_data": "https://storage.googleapis.com/labelbox-datasets/conversational-sample-data/pairwise_shopping_3.json",
"global_key": global_key_3
}
])
task.wait_till_done()
print("Errors:",task.errors)
print("Failed data rows:", task.failed_data_rows)
Conversation JSON
Max conversation size
For conversations, we support up to:- 250 messages.
- 10000 character limit per message
| Parameter | Required | Description |
|---|---|---|
type | Yes | This should always be populated with application/vnd.labelbox.conversational |
version | Yes | This should be populated with 1 |
messages | Yes | This is the array of Message Objects that makes up the conversation. Please see below for the fields that must be included for each message. The current maximum is 250 messages in a conversation |
Message object
| Parameter | Required | Description |
|---|---|---|
messageId | Yes | This is the external ID for the message. This must be unique within the conversation file and will be returned on the exports to help match annotations to message. |
timestampUsec | No | The unix epoch timestamp of the message. |
content | Yes | This field contains the text string of the conversation. This must be under 10000 characters. |
user | Yes | This field is used to describe the person that is speaking. The user defined by two fields: userId and name. The name field is used to show the user name in the editor. { "userId": "ID", "name": "Name" } |
align | No | This field Controls the alignment and indentation of the text string in the editor. If left blank, we will default to left. Options:left``0-left-indent``1-left-indent``2-left-indent``3-left-indent``4-left-indent``5-left-indent``right``0-right-indent``1-right-indent``2-right-indent``3-right-indent``4-right-indent``5-right-indent |
canLabel | Yes | This field determines if the text string can be annotated as a part of the editor workflow. If set to true, the editor will show a white background for the text string and the user will be able to annotated entities on the content string. If set to false, the editor will show a grey background for the text and the user will not be able to annotate the content string. |
Sample Conversation JSON
Note
You can’t upload the following file from the web interface directly. You must use an import file as described in Import format{
"type": "application/vnd.labelbox.conversational",
"version": 1,
"messages": [
{
"messageId": "message-0",
"timestampUsec": 1530718491,
"content": "I love iphone! i just bought new iphone! 🥰 📲",
"user": {
"userId": "Bot 002",
"name": "Bot"
},
"align": "left",
"canLabel": false
},
{
"messageId": "message-1",
"timestampUsec": 1530718503,
"content": "Thats good for you, i'm not very into new tech",
"user": {
"userId": "User 00686",
"name": "User"
},
"align": "right",
"canLabel": true
},
{
"messageId": "message-2",
"timestampUsec": 1530718516,
"content": "I am a college student and i am a college student 👩🏻🏫",
"user": {
"userId": "Bot 002",
"name": "Bot"
},
"align": "left",
"canLabel": false
},
{
"messageId": "message-3",
"timestampUsec": 1530718528,
"content": "I am go to gym and live on donations 🏋🏿♀️",
"user": {
"userId": "User 00686",
"name": "User"
},
"align": "right",
"canLabel": true
},
{
"messageId": "message-4",
"timestampUsec": 1530718540,
"content": "I am a vegan and i am in the midwest 🌱",
"user": {
"userId": "Bot 002",
"name": "Bot"
},
"align": "left",
"canLabel": false
},
{
"messageId": "message-5",
"timestampUsec": 1530718553,
"content": "So vegan... i have dogs maybe i should told then that they may eat cheap salads insted of meat 🐩",
"user": {
"userId": "User 00686",
"name": "User"
},
"align": "right",
"canLabel": true
},
{
"messageId": "message-6",
"timestampUsec": 1530718565,
"content": "I would not mind having them in the office that would be hard for me",
"user": {
"userId": "Bot 002",
"name": "Bot"
},
"align": "left",
"canLabel": false
},
{
"messageId": "message-7",
"timestampUsec": 1530718578,
"content": "Dogs or vegan in office?",
"user": {
"userId": "User 00686",
"name": "User"
},
"align": "right",
"canLabel": true
},
{
"messageId": "message-8",
"timestampUsec": 1530718590,
"content": "I am a vegetarian so i am vegan",
"user": {
"userId": "Bot 002",
"name": "Bot"
},
"align": "left",
"canLabel": false
},
{
"messageId": "message-9",
"timestampUsec": 1530718603,
"content": "Strange answer",
"user": {
"userId": "User 00686",
"name": "User"
},
"align": "right",
"canLabel": true
},
{
"messageId": "message-10",
"timestampUsec": 1530718615,
"content": "I guess i just do not know what to ps4 experience with.",
"user": {
"userId": "Bot 002",
"name": "Bot"
},
"align": "left",
"canLabel": false
}
]
}
Sample conversations in the editor view
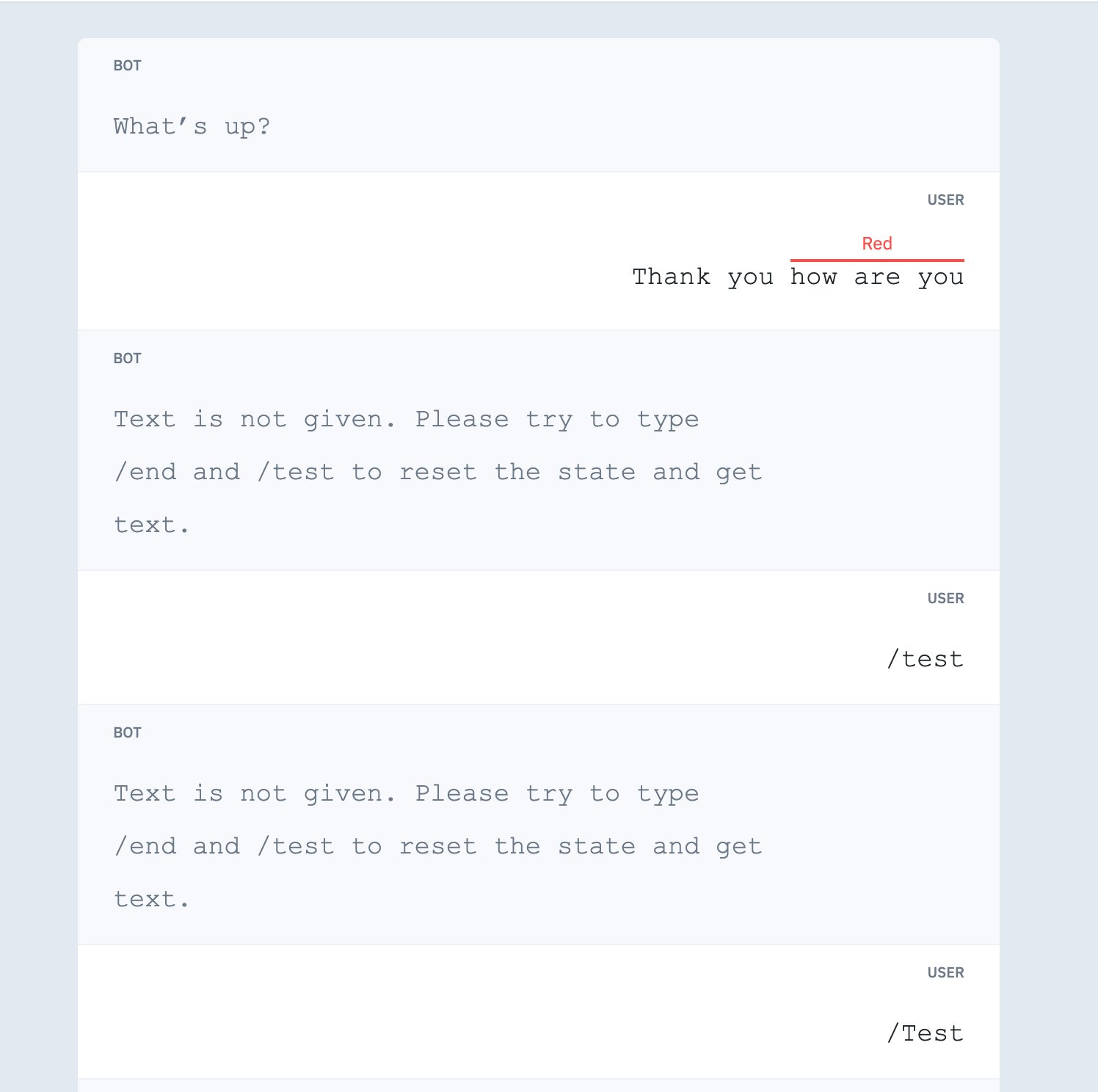
This is an example of a conversation using left and right alignment
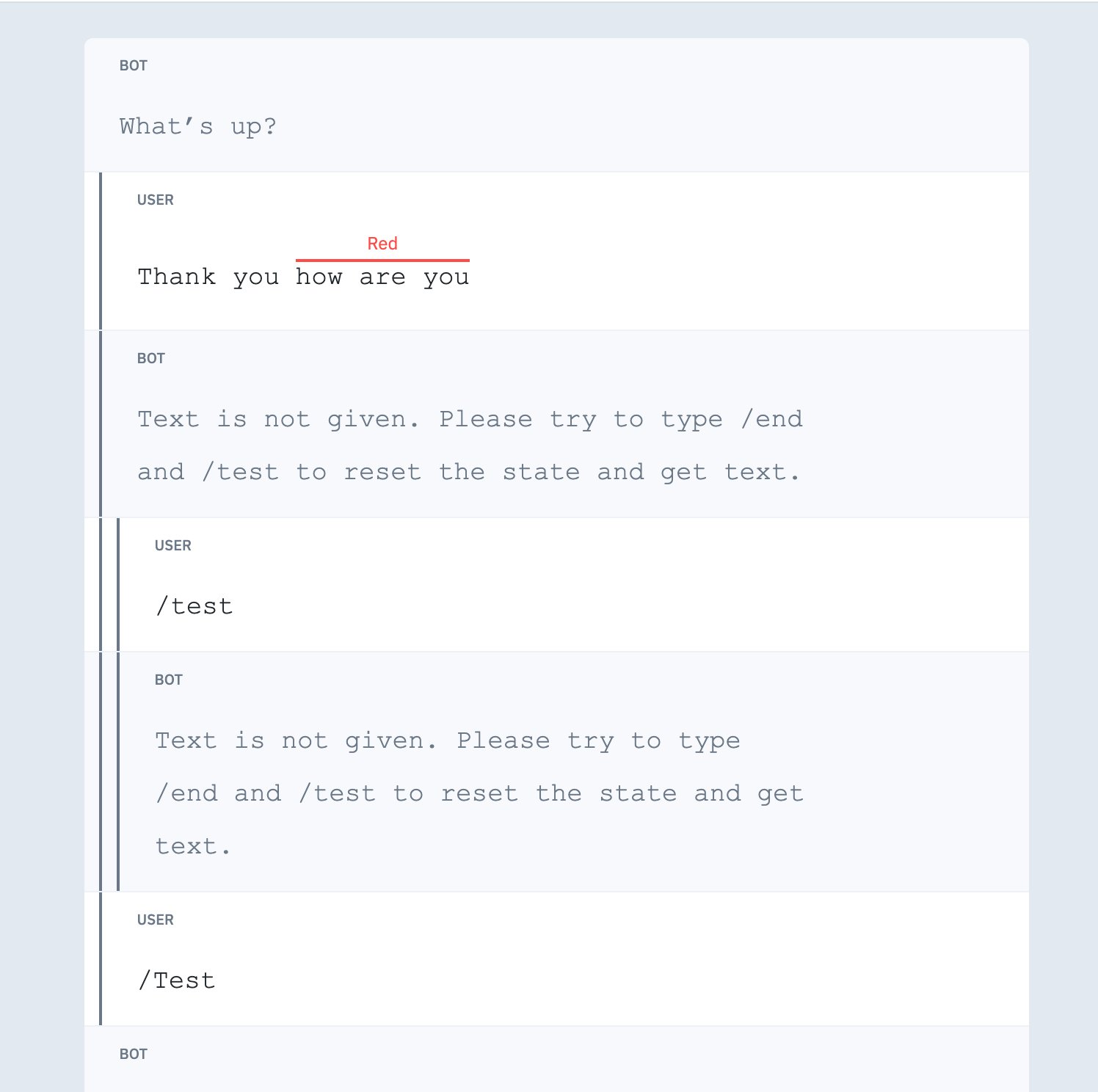
This is an example of a conversation using left indentation