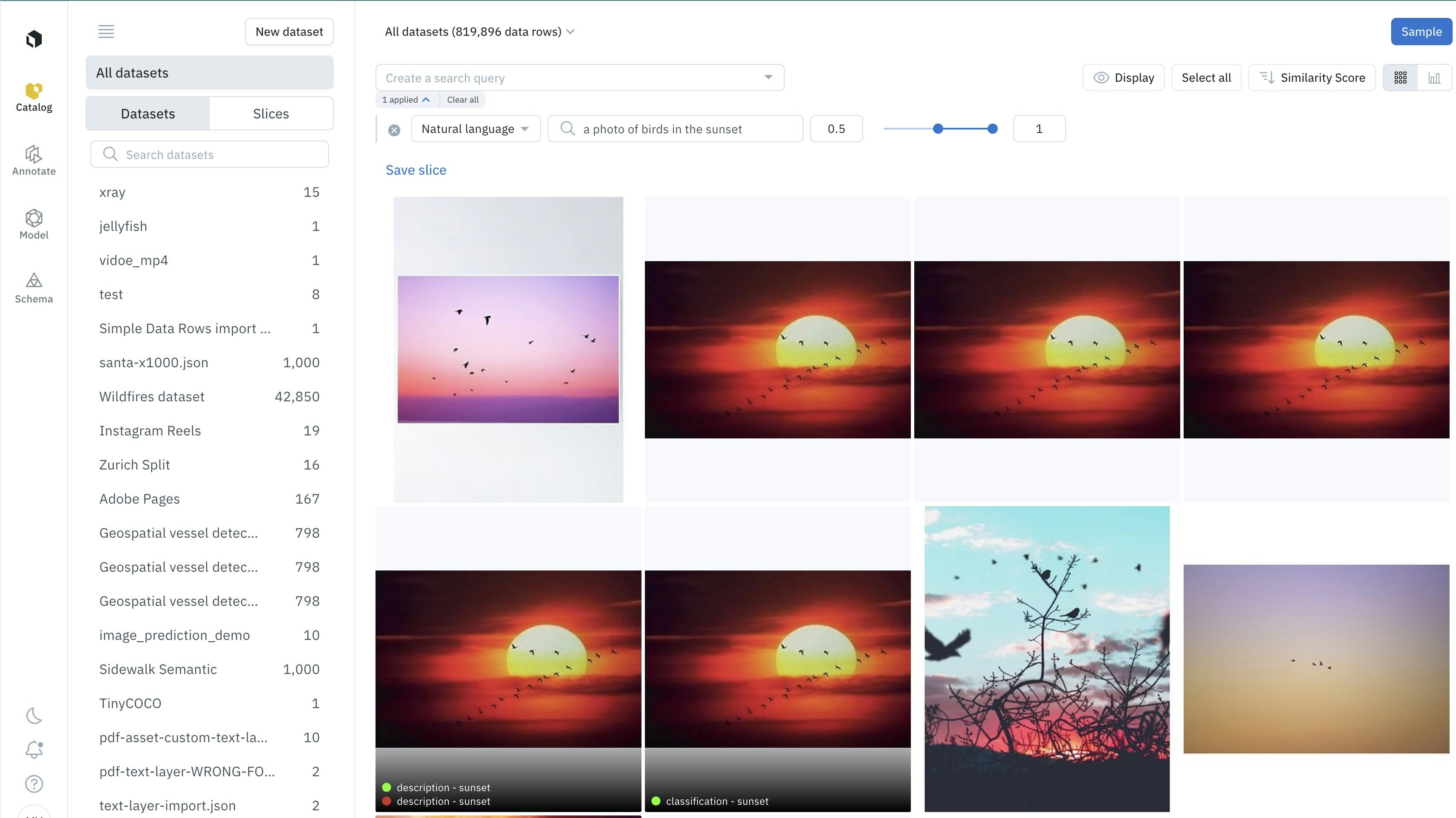
Natural language search for images
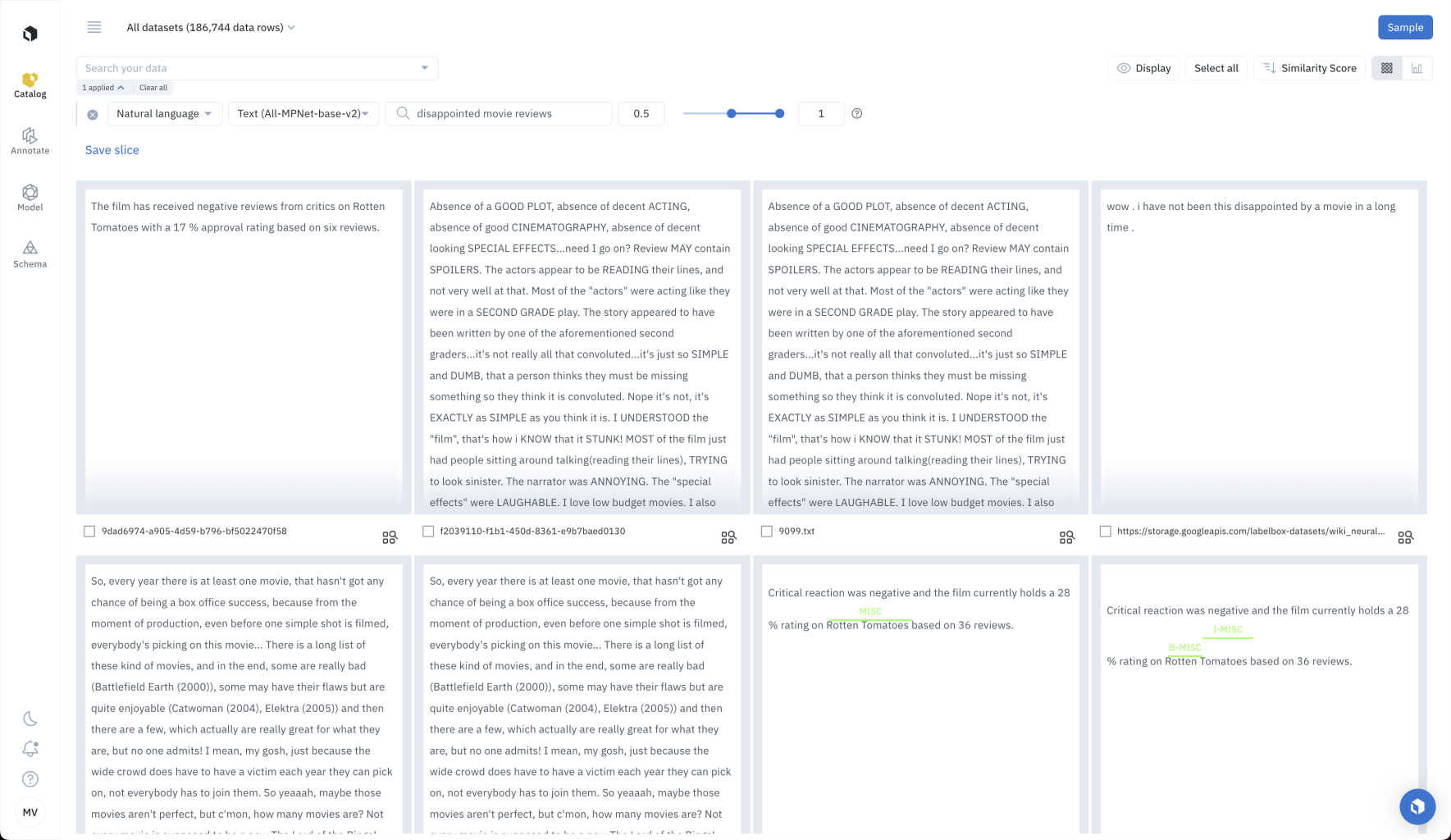
Natural language search for text
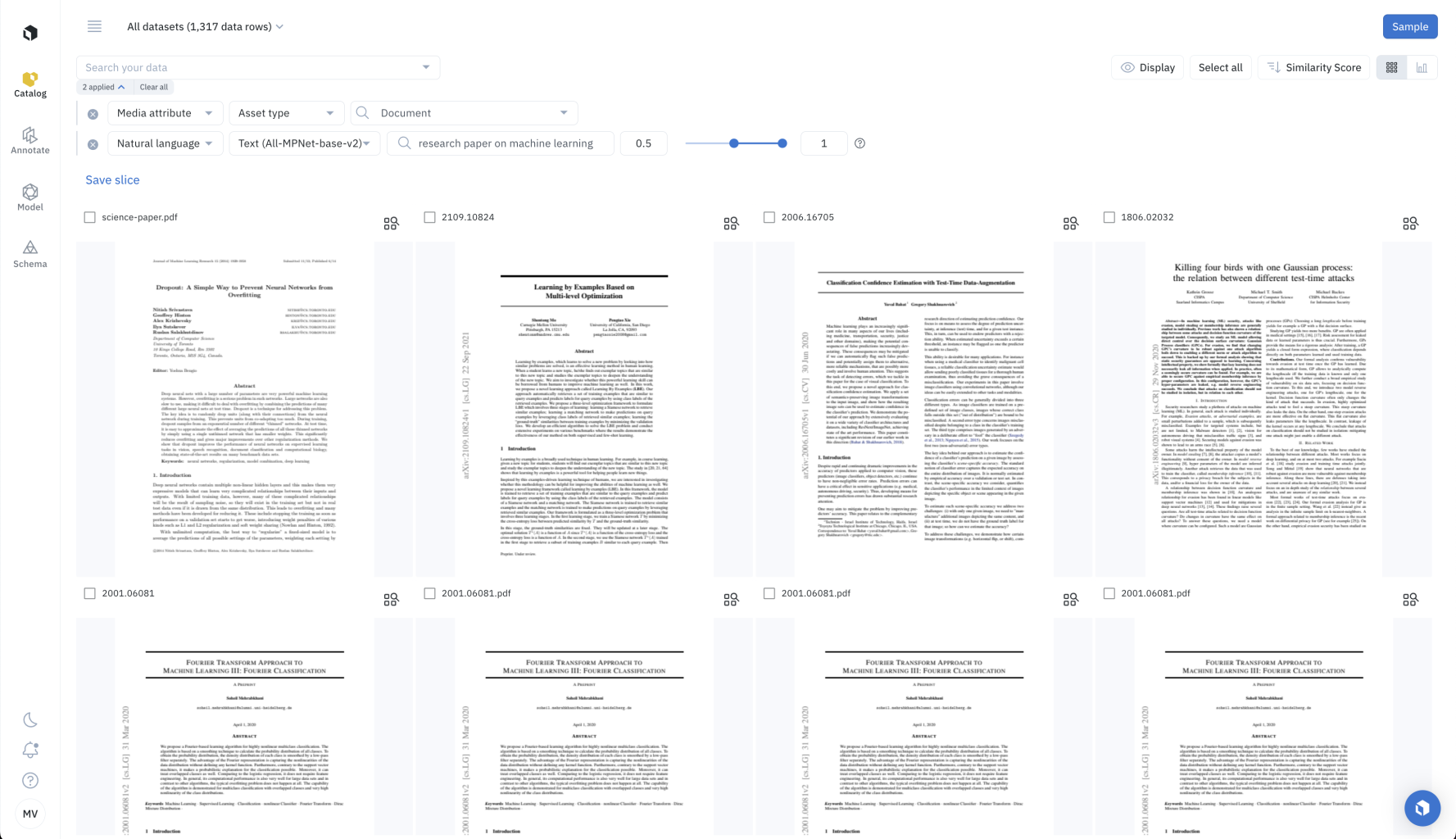
Natural language search for documents
How natural language search works
Natural language search is powered by vector embeddings. A vector embedding is a numerical representation of a piece of data (e.g., an image, text, document, or video) that translates the raw data into a lower-dimensional space. Recent advances in the machine learning field enable some neural networks (e.g., CLIP vision model by OpenAI or all-mpnet-base-v2 text model) to recognize a wide variety of visual concepts in images, texts, or documents and associate them with keywords. You can now surface images in Catalog by describing them in natural language. For example, type in “a photo of birds in the sunset” to surface images of birds in the sunset. You can also surface text, conversational text, or documents by describing them in natural language. For example, type in “disappointed movie reviews” to surface data rows that likely contain negative movie reviews.Supported media types
Labelbox supports natural language search for several data modalities. For each media type, the same neural network embeds both the user query and the data row. Below is the list of neural networks used for each media type.How to search data using natural language
In the gallery view of Catalog, select the Natural language filter. Then, decide if you want to do a Visual search or Text search. Finally, input the description of the data you are looking for. The description must have at least 3 characters and at most 10 words.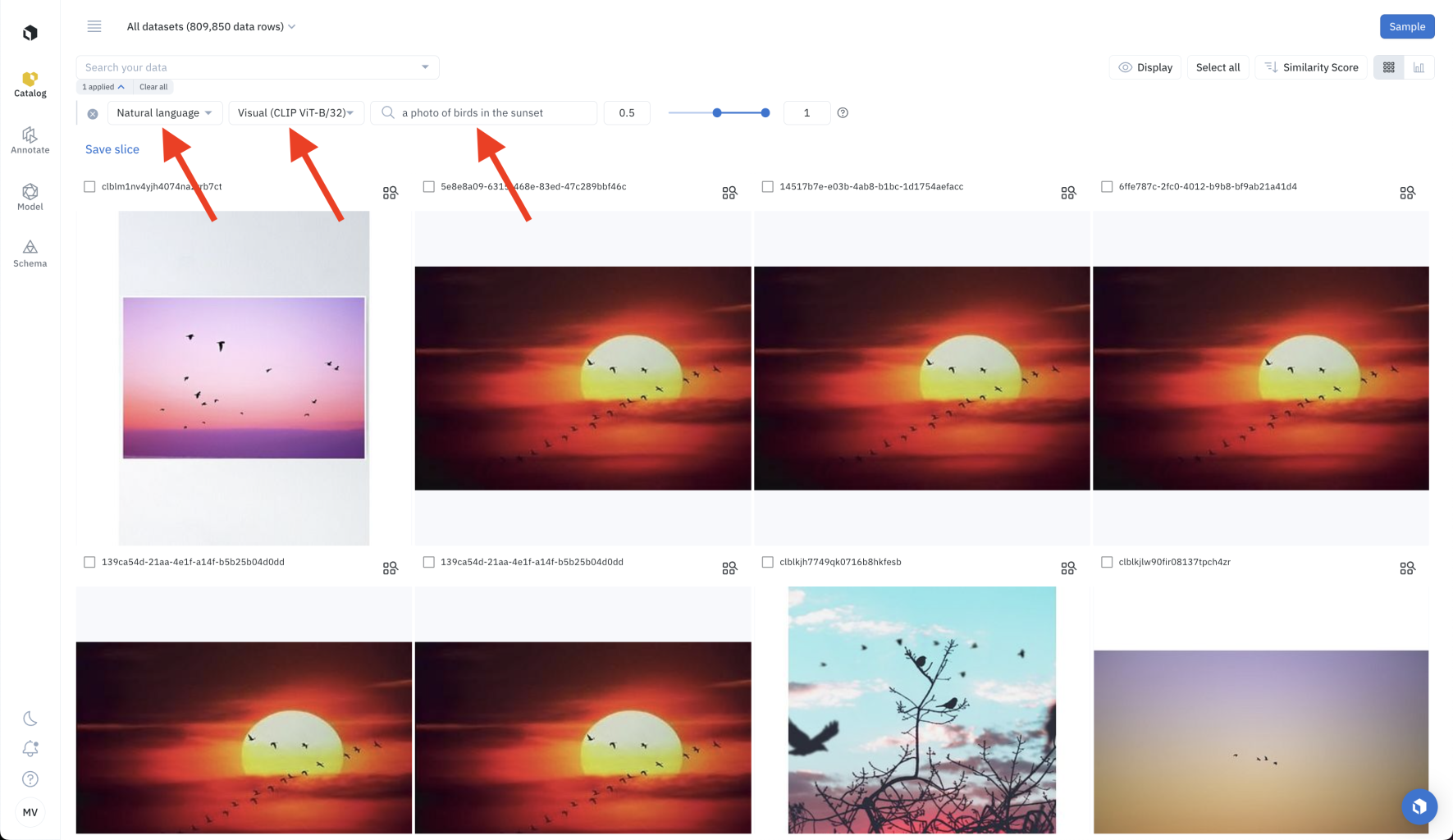
Natural language search for images
Prompt engineering
Prompt engineering involves trying several prompts until finding one that works well. Labelbox recommends trying several natural language descriptions (or prompts) until the natural language search surfaces the data you are looking for. Users have reported that small tweaks to the prompt can help return more relevant data. You can refine your prompt by adding positive biases and negative biases, using this prompt structure:[my prompt] / [more of this positive bias] / [less of this negative bias].
For example, I can refine my search for a photo of birds in the sunset, by asking for purple sunsets and not red sunsets, with the prompt: a photo of birds in the sunset / purple / red. This returns only images of birds in a purple sunset, and not in a red sunset.
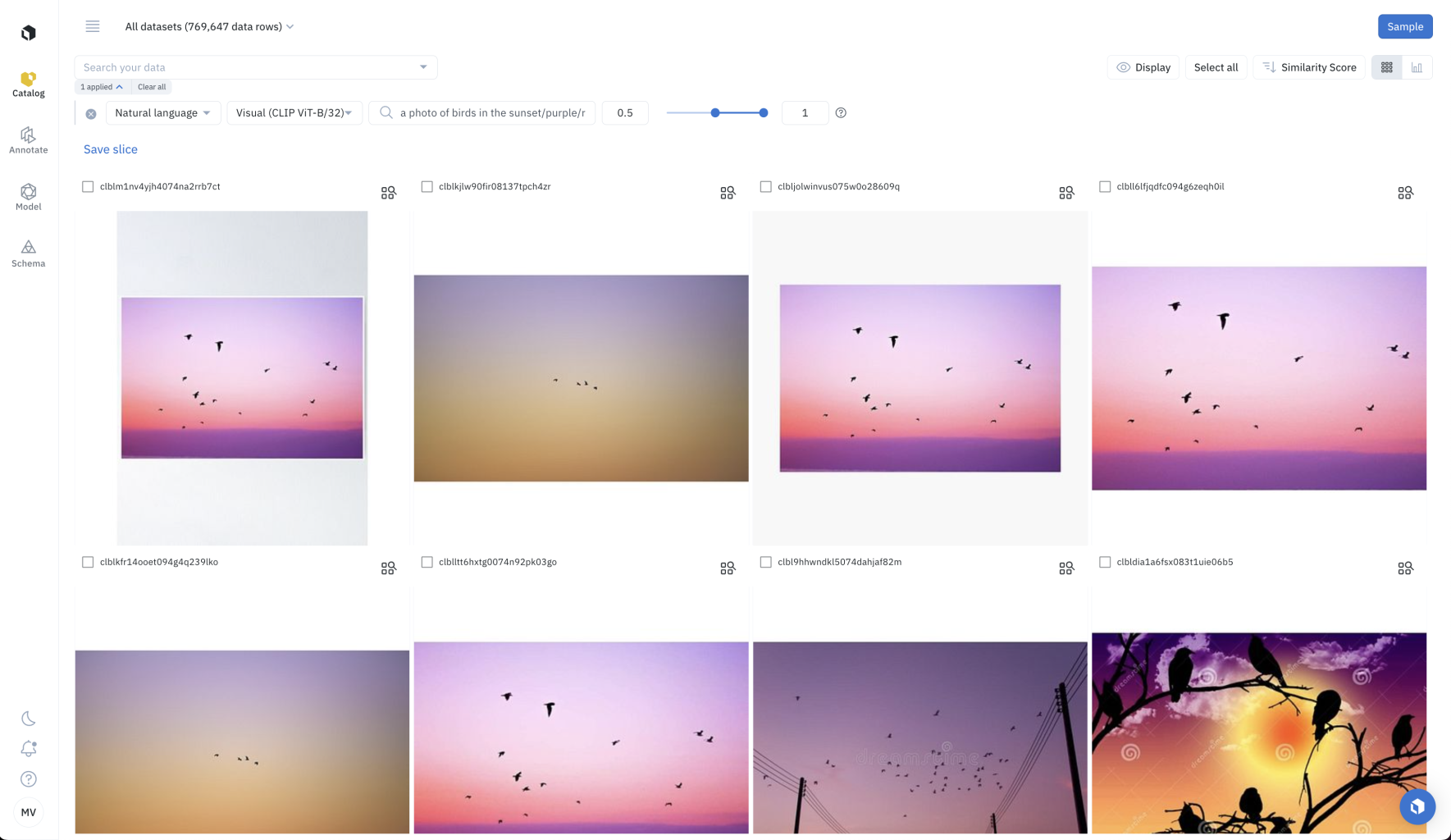
Advanced prompt to keep only purple sunsets and remove red sunsets: a photo of birds in the sunset / purple / red
Set the score range
Natural language search surfaces the data rows whose embeddings are closest to the prompt. This is measured using cosine distance, a number between 0 and 1. The more similar the embeddings, the higher the natural language score. By default, Labelbox returns embeddings with a natural language score between 0.5 and 1. You can customize this range by setting the minimum and maximum values of the natural language search slider.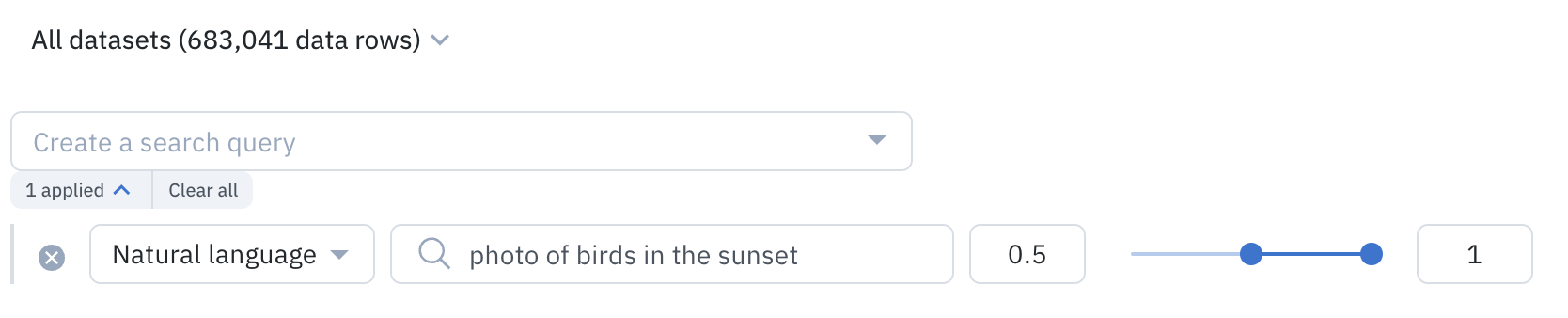
Customize the results of the natural language search by specifying the range of scores.
Combine natural language search & other searches
You can combine natural language search with other filters in Catalog. Some filters are best used for targeting unstructured data, and others for targeting structured data. Combine natural language search with the following filters to target data rows by structured data:Metadata
Annotations
Datasets
Projects
Similarity search
Text search
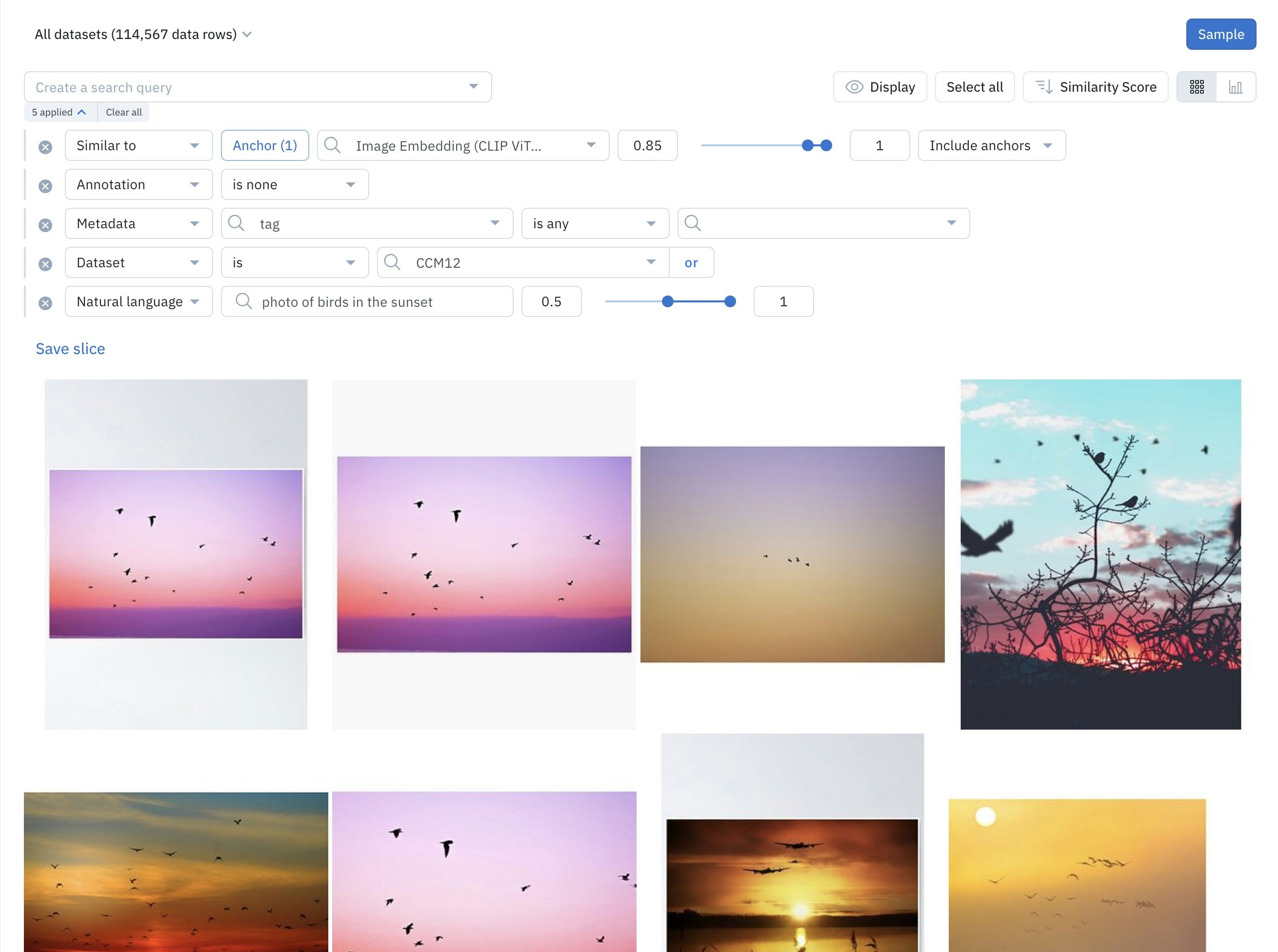
Use natural language search with other filters to surface high-impact data.