How to use similarity search
The easiest way to get started with similarity search is to use the pre-computed embeddings that Labelbox provides for common data types. To perform a similarity search:- Find an anchor: In the Catalog, hover over a data row you want to find more examples of and click the Find similar data icon. This initial data row will be your “anchor”.
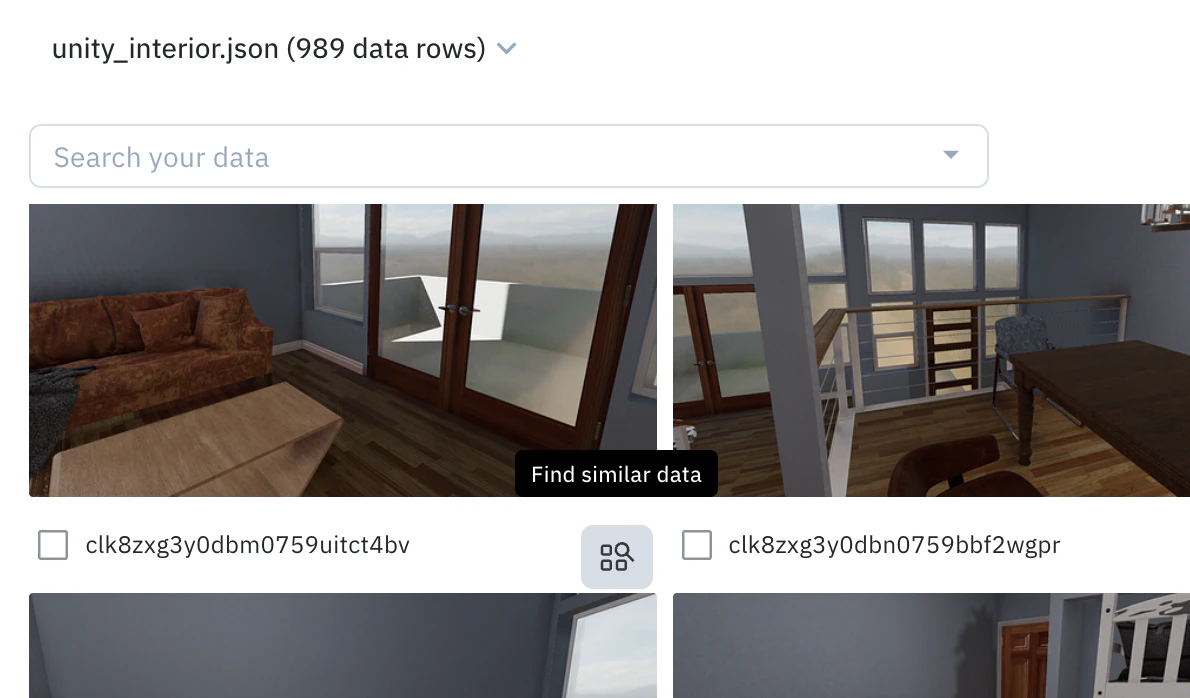
- Add more anchors: You can optionally select multiple data rows to use as anchors and then select Add selection as anchors.
- Refine your results:
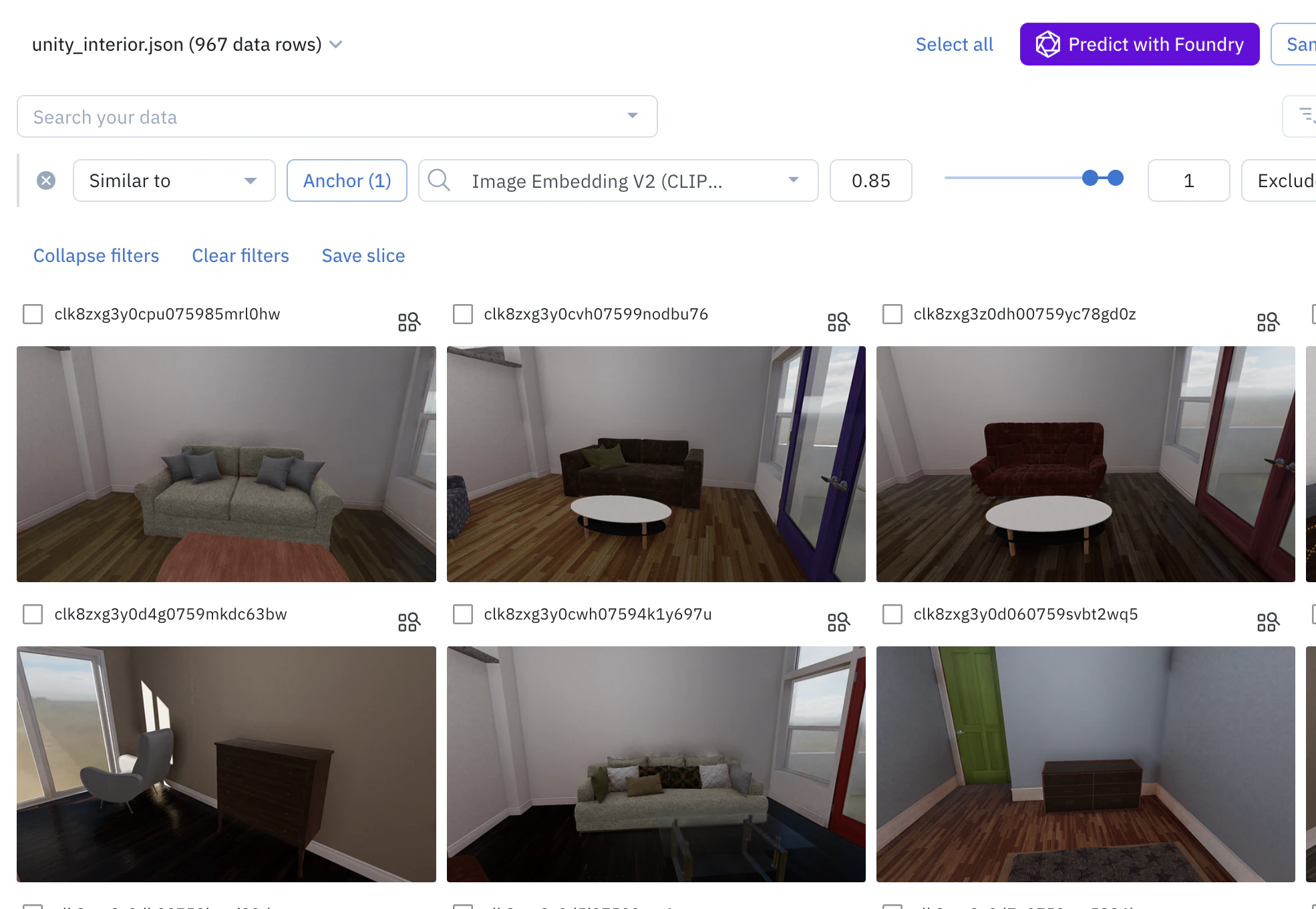
- Add or remove anchors: To add more examples and refine the search, select more data rows and click “Add selection to anchors”. To remove an anchor, click on “Anchors (n)” to view all anchors, and click the ”—” icon on the one you want to remove.
- Adjust the similarity score: You can adjust the range of the similarity score (from 0 to 1) to broaden or narrow your search. A higher score means the results will be more similar to your anchors.
How to use your own embeddings
If you have your own embeddings, you can upload them to Labelbox to use in similarity searches.View the limits page to learn the custom embedding limits per workspace and the maximum dimensions allowed per custom embedding.
- Create an API key.
- Navigate to Schema > Embeddings.
- Click + Create and give your embedding a name and specify the number of dimensions.
- Once created, you can use this Google Colab notebook to upload your custom embeddings. You can view all of the embedding fields in JSON format by clicking the </> button.