- Benchmarking allows you to designate a labeled data row as a gold standard for other labels. It’s useful for assessing the accuracy of annotations.
- Consensus scoring compares annotations on the same data row by different labelers to determine a consensus winner. It’s useful for facilitating immediate corrective actions to improve both training data and model performance.
View and assess quality analysis performance
On a project’s Data Rows tab, you can view the average benchmark and consensus agreement scores for each benchmark data row, along with the number of labels associated with the consensus agreement. Additionally, you can assess performance using these scores on the Performance tab:- Labeler performance: In the Members Performance section, click on an individual labeler to see their average benchmark and consensus scores.
- Overall project performance: Under Performance charts > Quality, the left histogram shows the average benchmark score by date range, and the right histogram displays the number of labels within specific benchmark score ranges.
Export quality analysis scores
You can export labels along with their benchmark and consensus agreement scores using the SDK. For every exported label with a benchmark or consensus agreement, you can find theirbenchmark_score and consensus-score values in the performance_details section of exported labels in the resulting JSON file.
For a benchmark data row labeled multiple times, all non-benchmark labels contain a benchmark_reference_label field, which is the ID of the benchmark label they reference. The benchmark label itself doesn’t have a benchmark_reference_label field or an associated benchmark score, as it serves as the standard for comparison, not as a label being compared.
Calculation methodologies
Benchmark and consensus agreement scores for different types of labels are calculated using different methodologies. The scores for each annotation type are averaged to produce an overall benchmark score for a data row, which helps assess the accuracy and consistency of labels.Benchmarking methodologies
Object-type annotations
The benchmark agreement for bounding box, polygon, and segmentation mask annotations is calculated using Intersection over Union (IoU). The agreement between point annotations and polyline annotations is calculated based on proximity.- First, Labelbox compares each annotation to its corresponding benchmark annotation to generate IoU scores for each annotation. The algorithm first finds the pairs of annotations to maximize the total IoU score, then it assigns an IoU value of 0 for the unmatched annotations.
- Then, Labelbox averages the IoU scores for each annotation belonging to the same annotation class to create an overall score for that annotation class.
Classifications
The calculation for each classification type varies. One commonality, however, is that if two classifications of the same type are compared and there are no corresponding selections between the two classifications at all, the agreement will be 0%.- A radio classification can only have one selected answer. Therefore, the agreement between the two radio classifications will either be 0% or 100%. 0% means no agreement and 100% means agreement.
- A checklist classification can have more than one selected answer, which makes the agreement calculation a little more complex. The agreement between two checklist classifications is generated by dividing the number of overlapping answers by the number of selected answers.
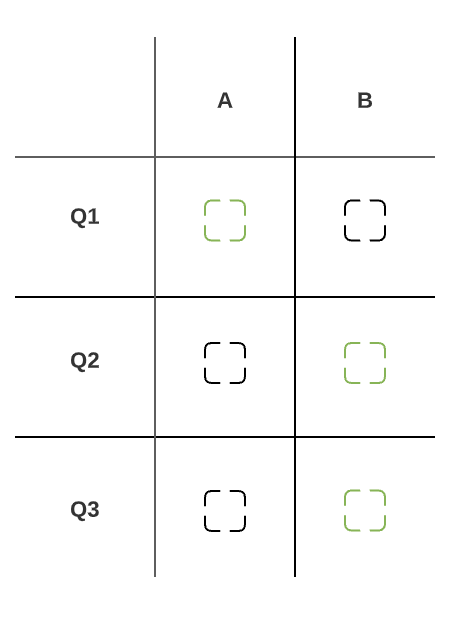
- Q1-A: 1
- Q1-B: N/A <— not included in the final calculation.
- Q2-A: 0
- Q2-B: 0
- Q3-A: 0
- Q3-B: 0
Overall score
Labelbox averages the scores for each annotation class (object-type & classification-type) to create an overall score for the asset. Each annotation class is weighted equally. Below is a simplified example: Benchmark score = (tree annotation class agreement + radio class agreement) / total annotation classes 0.795 = (0.59 + 1.00) / 2 For text and conversations, such as human-generated responses from prompt and response generation, Labelbox also creates a model-based similarity score that accounts for various ways of expressing the same idea, such as using active versus passive voice, synonyms for the same concept, and other variations in writing style. You can use this metric as an initial indicator of label quality, the clarity of your ontology, and/or the clarity of your labeling instructions.Consensus scoring methodologies
Labels used in calculation
While you can submit any number of labels for a given asset, Labelbox only includes a subset of those labels when calculating the consensus score. For most data types, up to 20 labels are used in the calculation. For the free-form text classification type, only 5 labels are used in the calculation. These limits help ensure efficient and consistent consensus score evaluations, especially in large-scale labeling projects.Object-type annotations
Consensus agreement for bounding box, polygon, and segmentation mask annotations is calculated using Intersection over Union (IoU). The agreement between point annotations and polyline annotations is calculated based on proximity.- First, Labelbox compares each annotation to its corresponding annotation to generate IoU scores for each annotation. The algorithm first finds the pairs of annotations to maximize the total IoU score, then it assigns the IoU value of 0 to any unmatched annotations.
- Labelbox then averages the IoU scores for each annotation belonging to the same annotation class to create an overall score for that annotation class.
Text (NER) annotations
The consensus score for two text entity annotations is calculated at the character level. If two entity annotations do not overlap, the consensus score will be 0. Overlapping text entity annotations will have a non-zero score. When there is overlap, Labelbox computes the weighted sum of the overlap length ratios, discounting for already counted overlaps. Whitespace is included in the calculation.- Since the consensus agreement for NER is calculated at the character level, spans of text are partly inclusive. For example, If two labelers make an overlapping text entity annotation on the word “house” and the first labeler submits an annotation with
houseand the second labeler submits an annotation on the same word in the text file withhous, the agreement score between these two annotations would be 0.80. - Labelbox then averages the agreements for each annotation created using that annotation class to create an overall score for that annotation class.
Classifications
The calculation method for each classification type is different. One commonality, however, is that if two classifications of the same type are compared, and there are no corresponding selections between the two classifications at all, the agreement will be 0%.- A radio classification can only have one selected answer. Therefore, the agreement between the two radio classifications will either be 0% or 100%. 0% means no agreement, and 100% means agreement.
- A checklist classification can have more than one selected answer, which makes the agreement calculation a little more complex. The agreement between two checklist classifications is generated by dividing the number of overlapping answers by the number of selected answers.
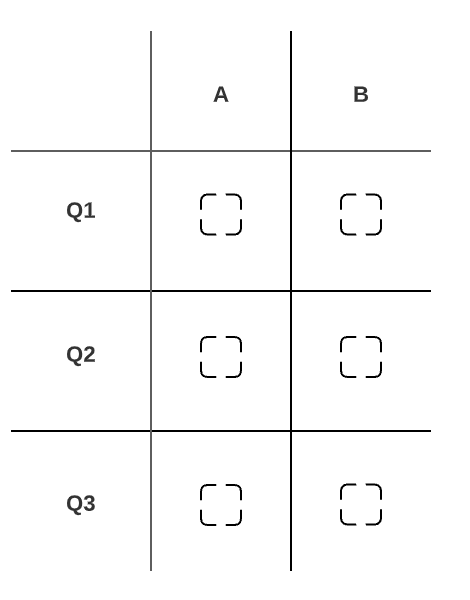
Each of the dotted boxes represents a unique answer choice/answer schema.
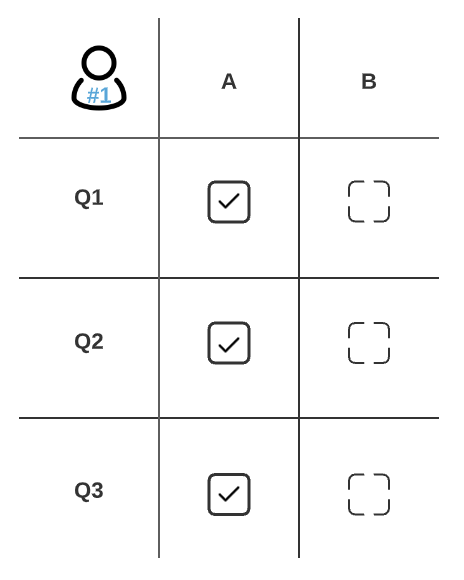
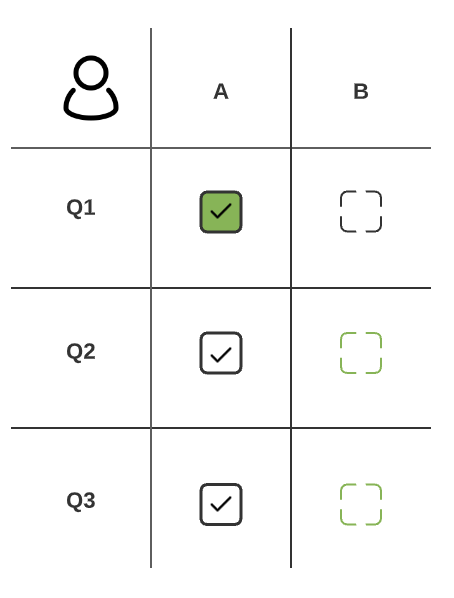
Labeler 1
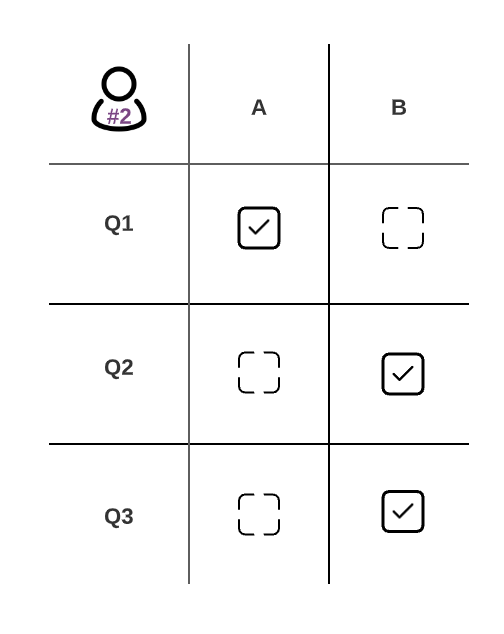
Labeler 2
- Q1-A: 1 (both labelers picked this answer)
- Q1-B: N/A (neither labeler picked this answer) <— not included in the final calculation.
- Q2-A: 0 (Labeler 1 selected, Labeler 2 did not)
- Q2-B: 0 (Labeler 2 selected, Labeler 1 did not)
- Q3-A: 0 (Labeler 1 selected, Labeler 2 did not)
- Q3-B: 0 (Labeler 2 selected, Labeler 1 did not)