- Ontologies involving unique or uncommon features
- Unique data distributions that general models do not typically support
- Create an experiment to prepare training data
- Use experiment results to fine-tune a base model
- Use the tuned model to perform model runs on untrained data.
Prepare training data
To begin, add data rows and ground truth labels to a model experiment Model Run- Select data rows and add them to a new experiment.
- Configure your experiment
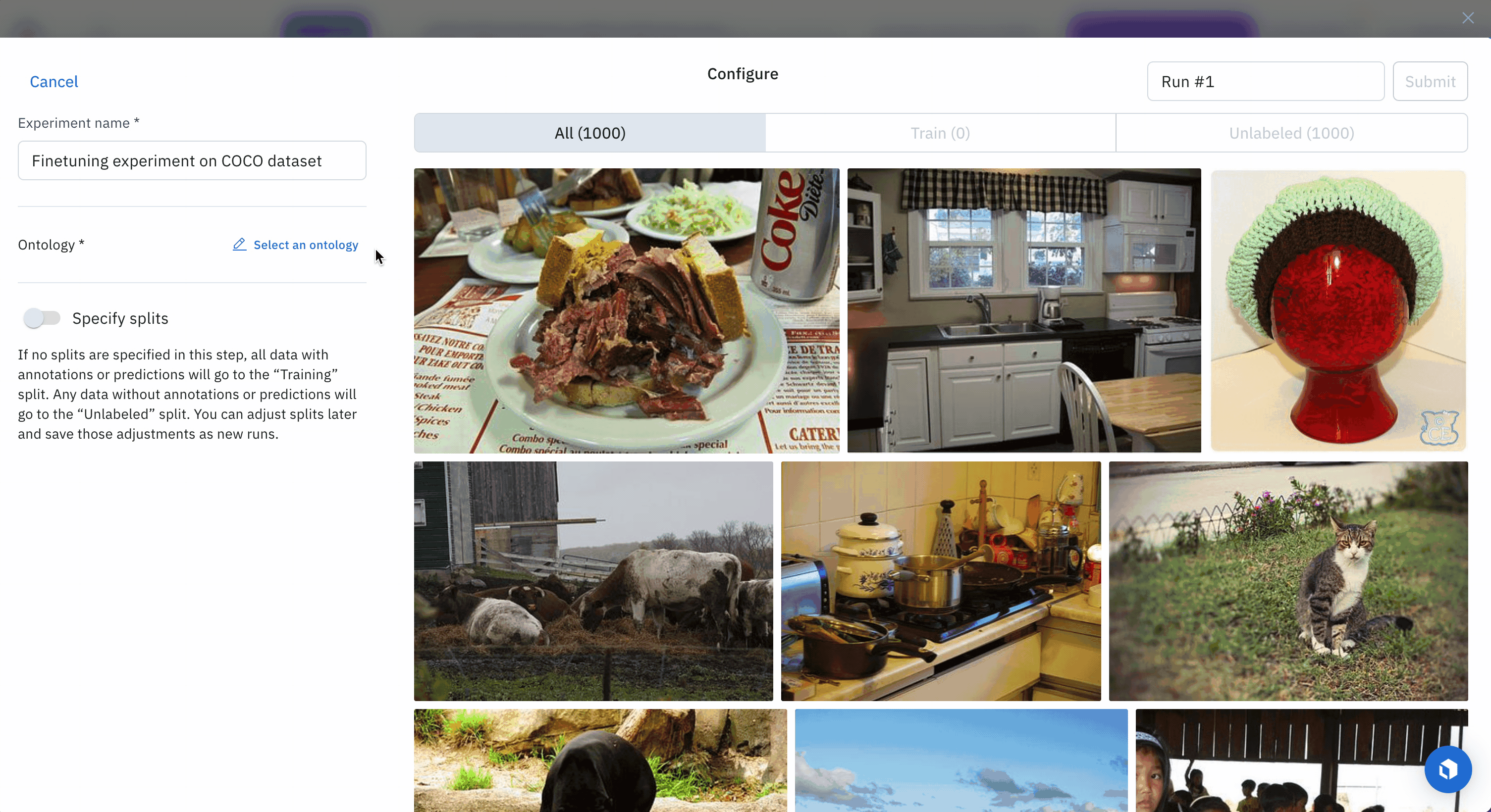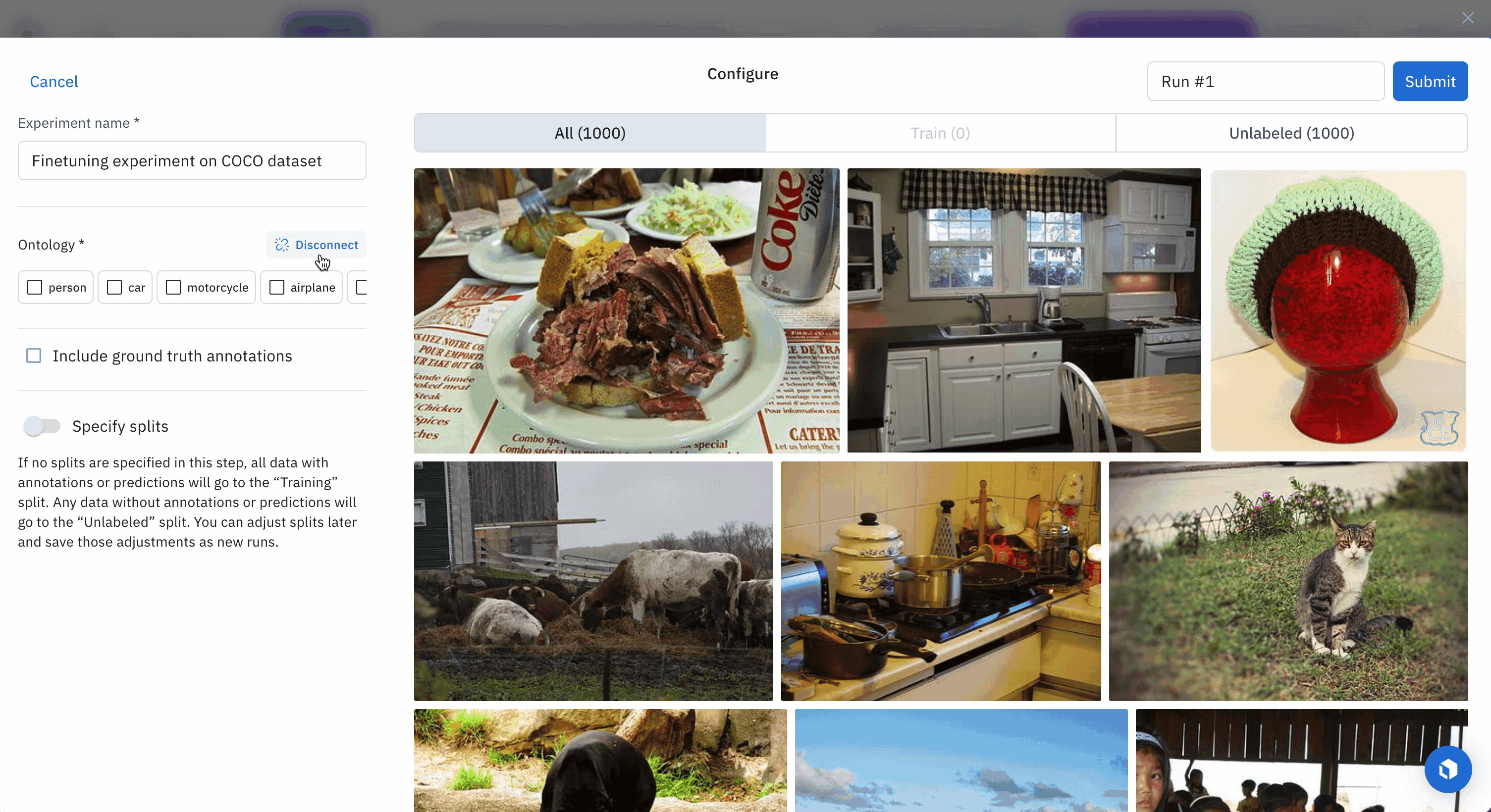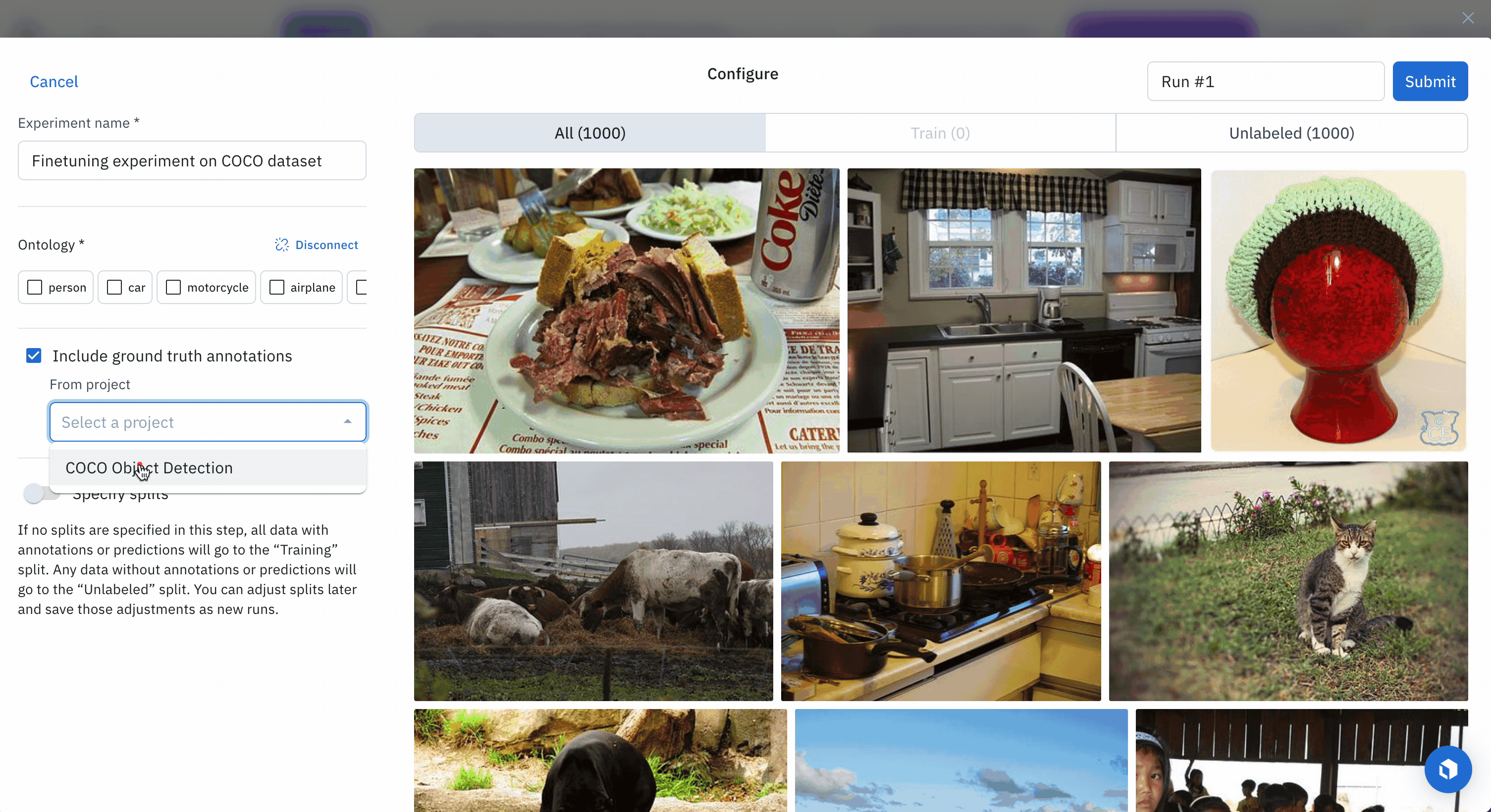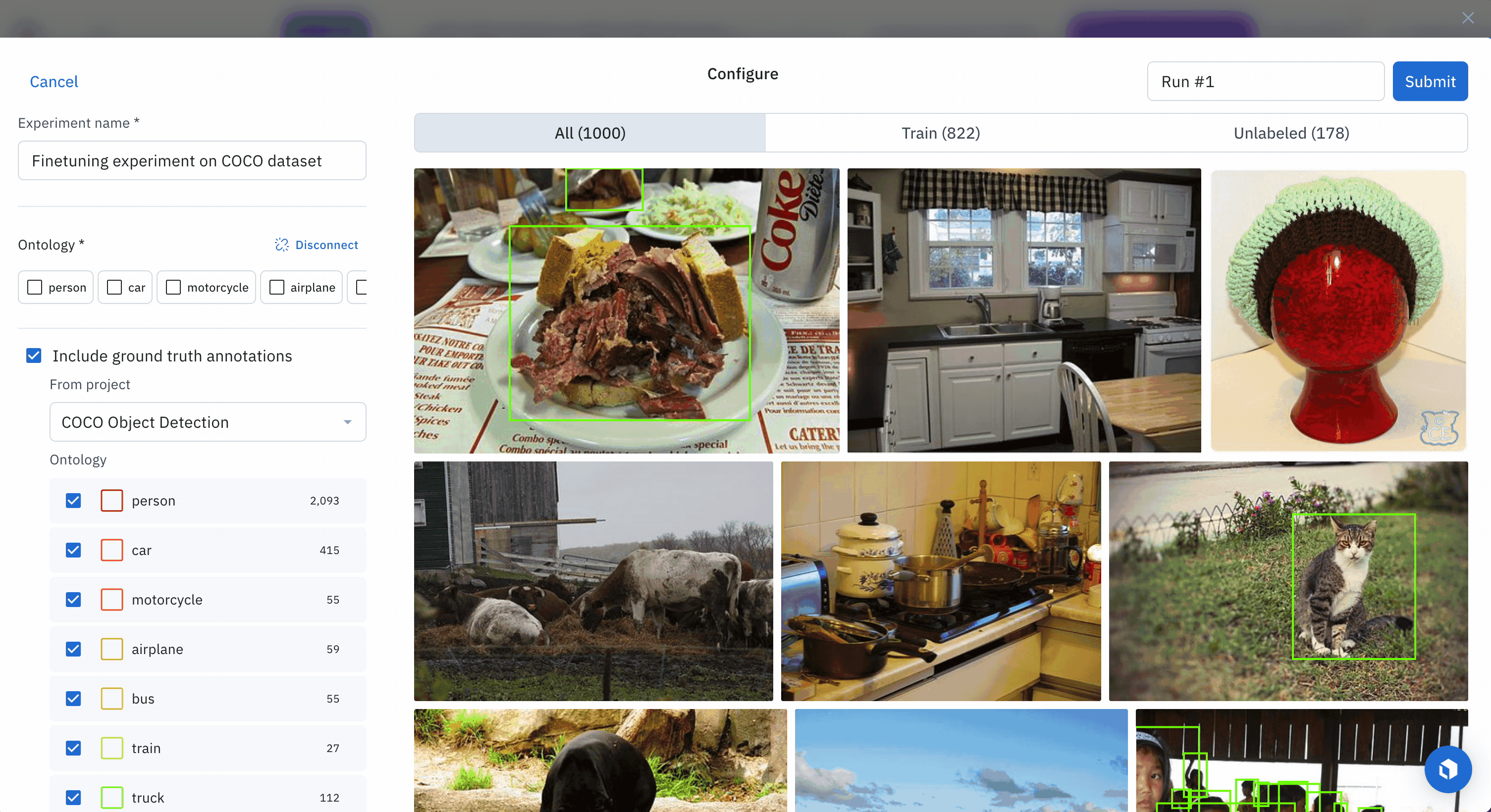
- Provide an ontology
- Define split
- Name and submit your experiment as a training model run.
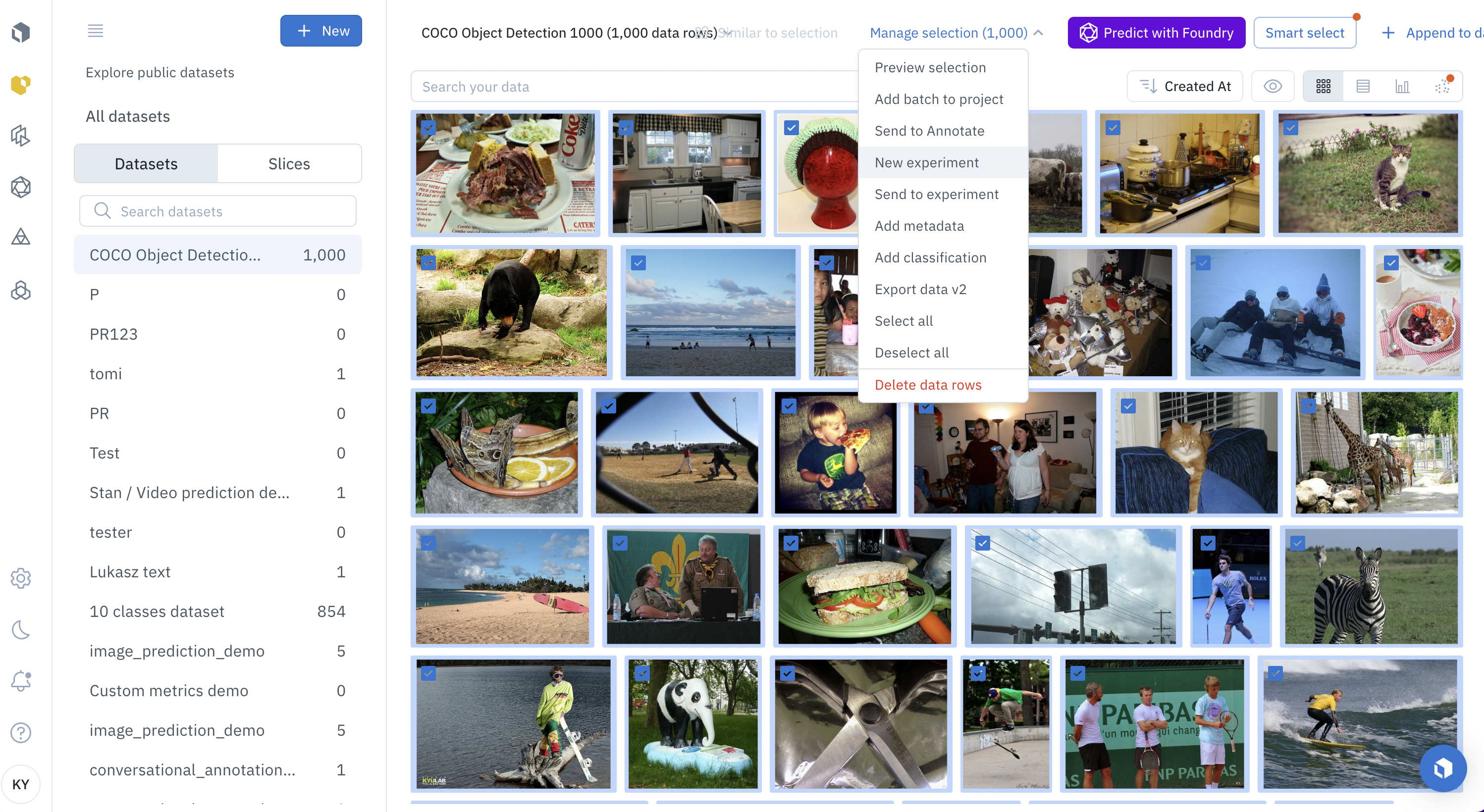
Select 1000 data rows, click Select all, then click New experiment to create an experiment for this fine-tuning job.

Fine-tune a model
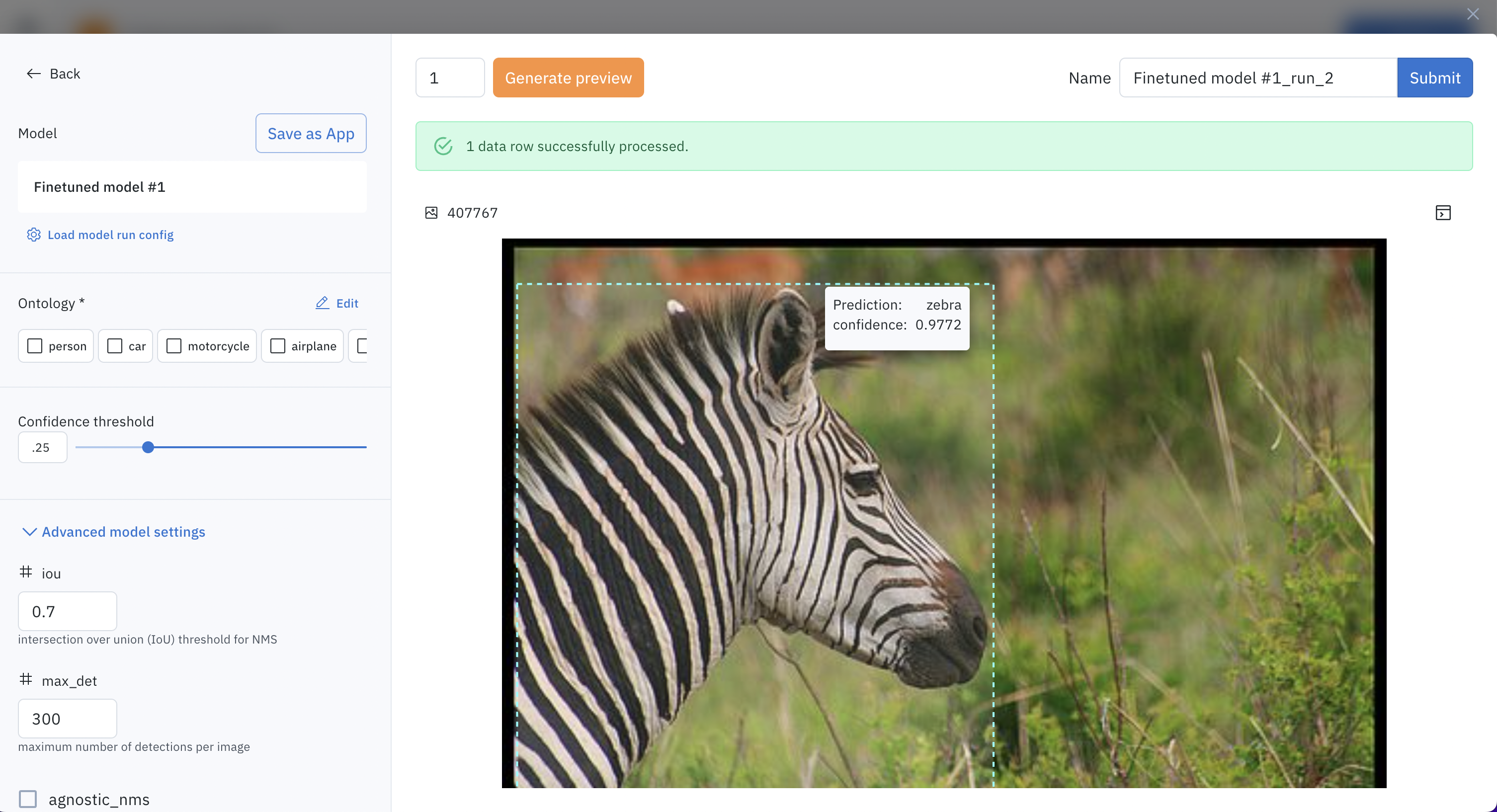
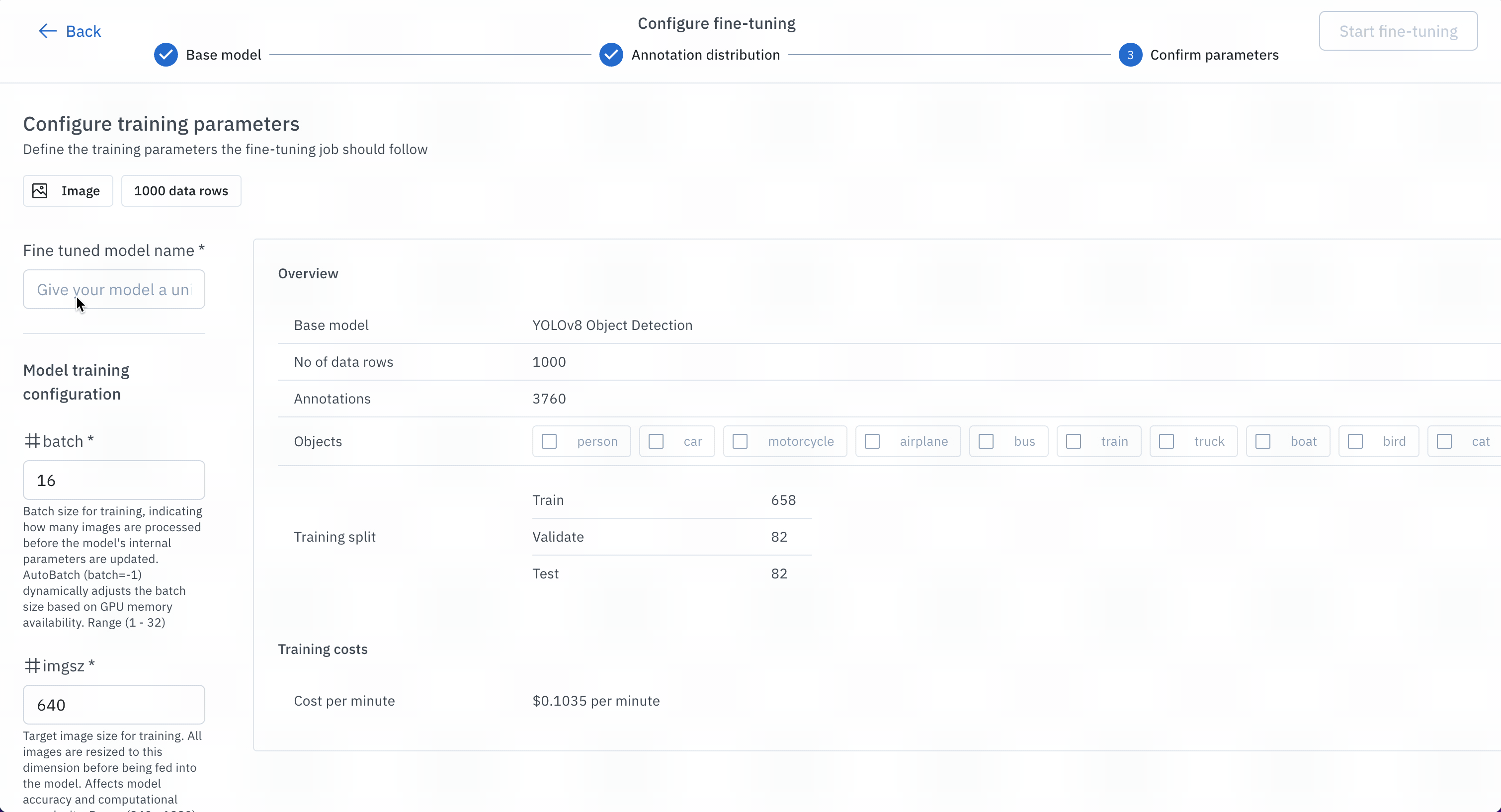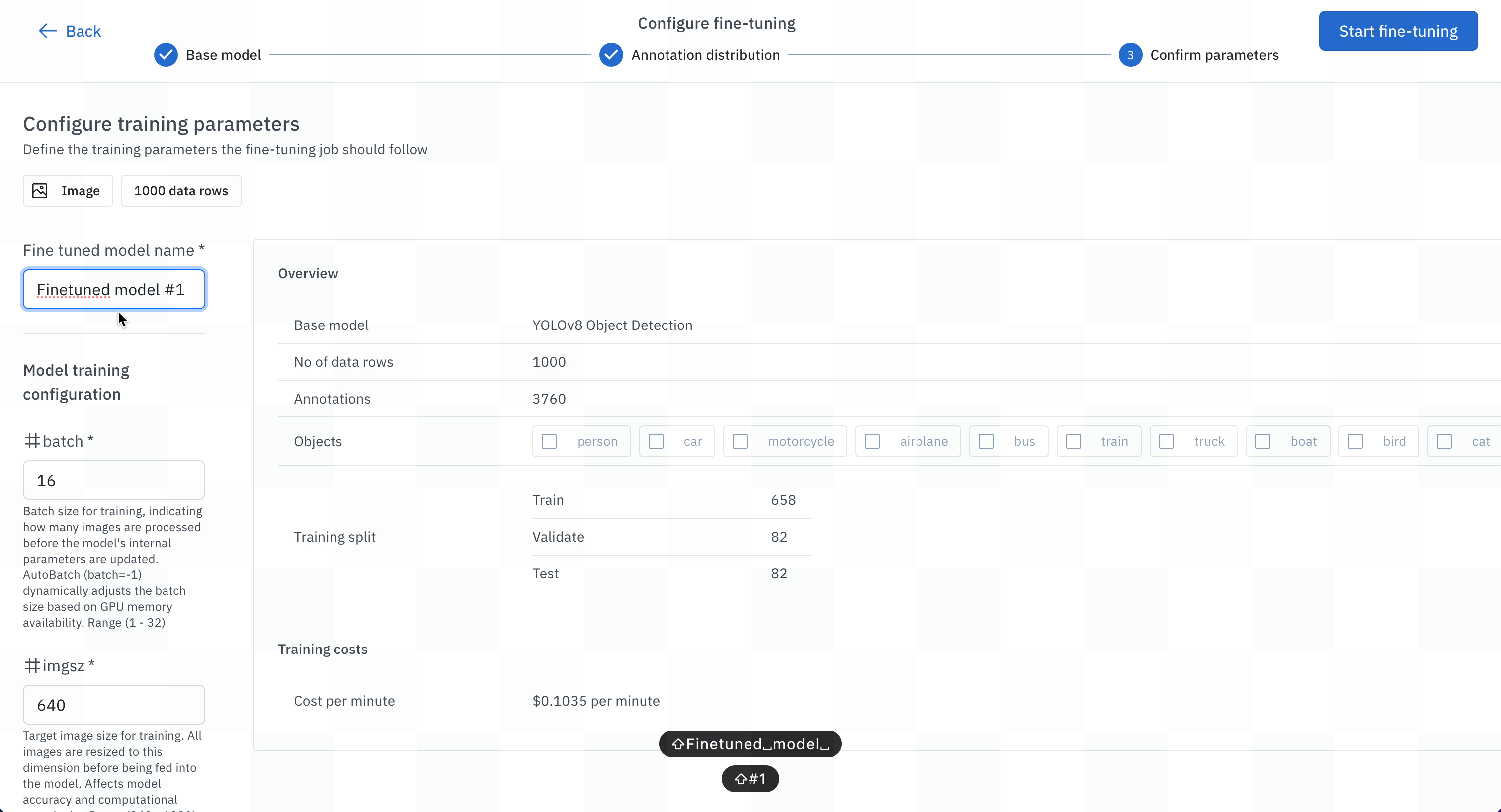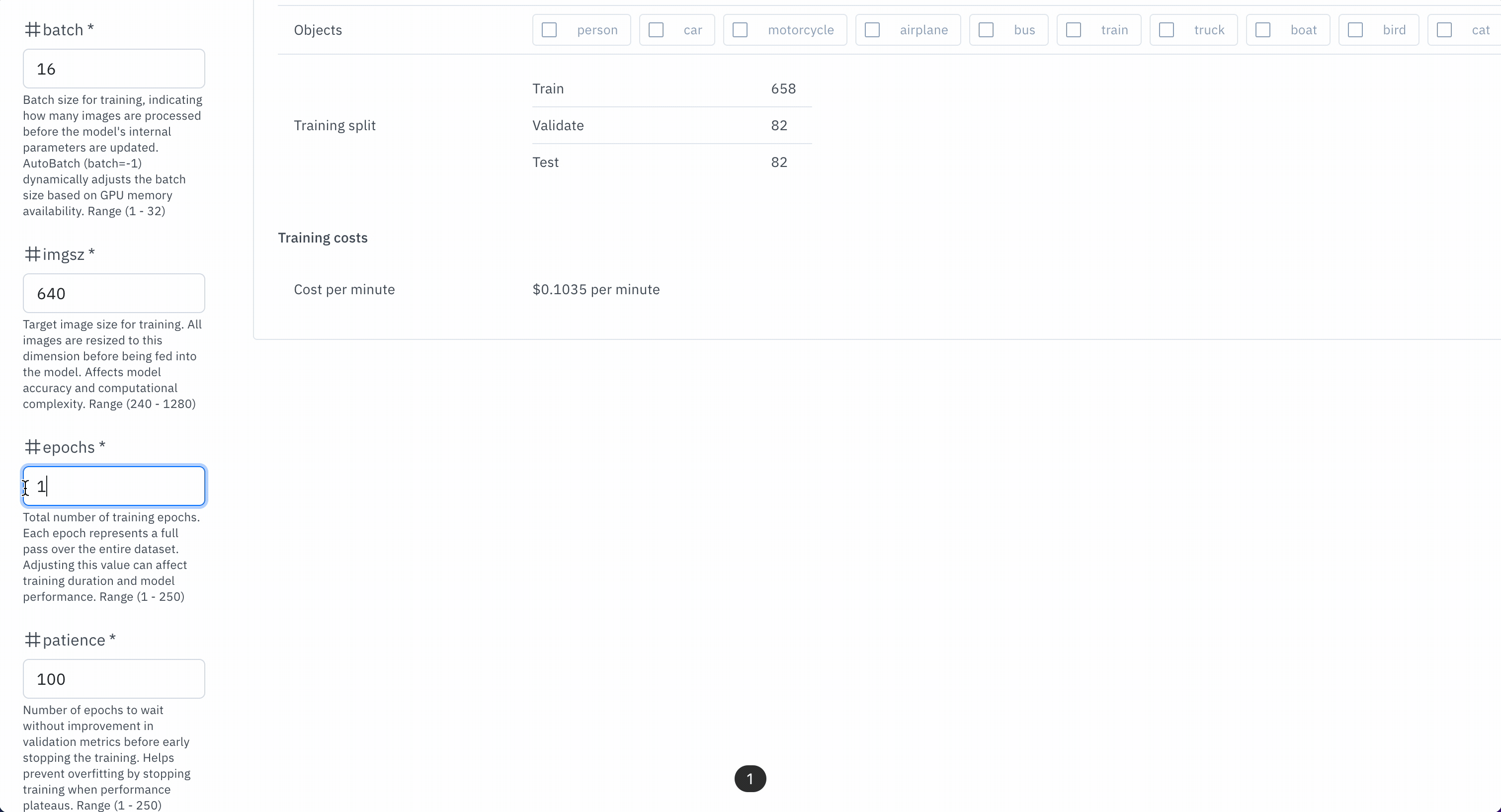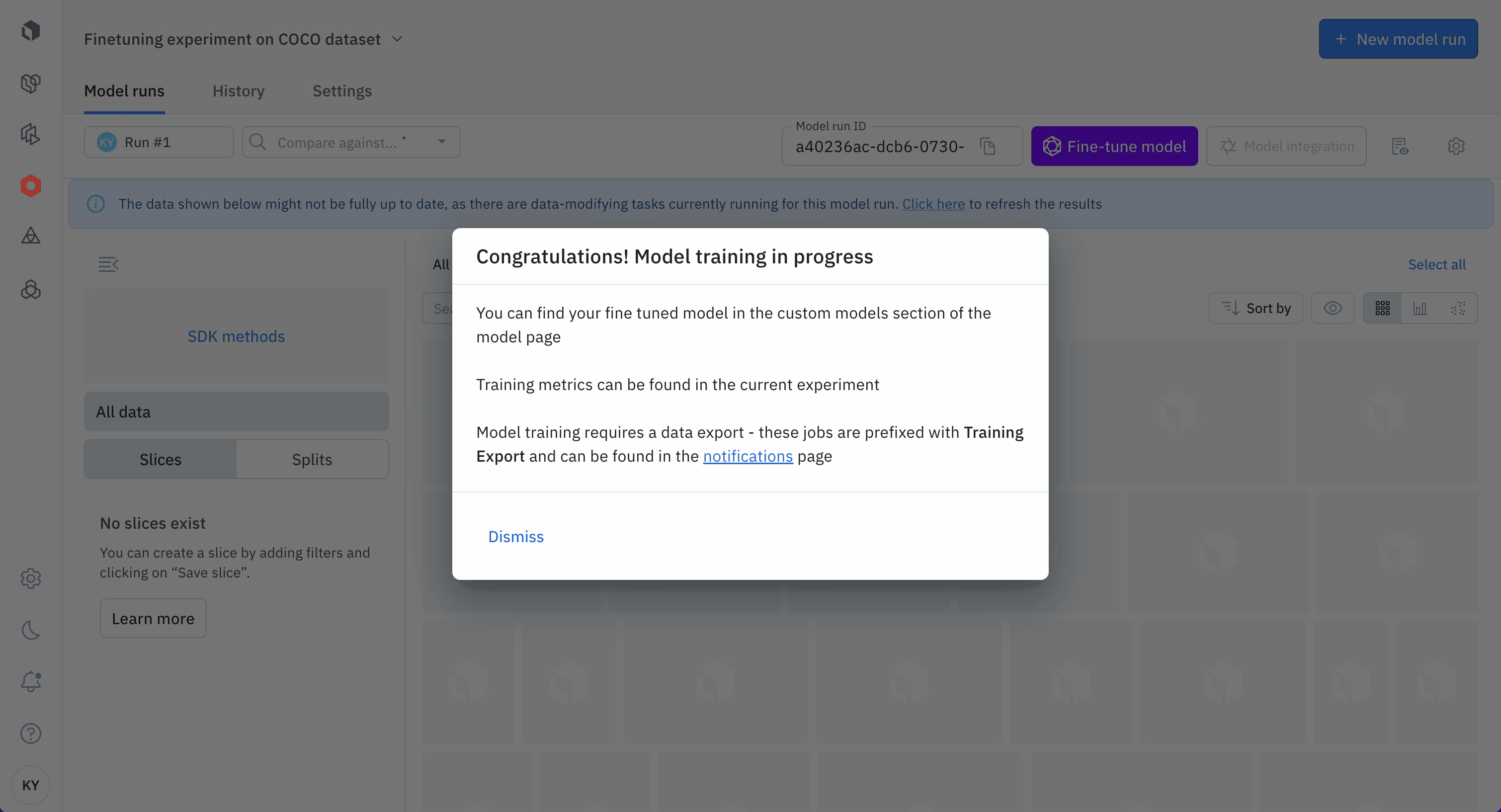
In the Model runs tab, you should see the labeled data you have sent. To start the fine-tuning, select Fine-tune model.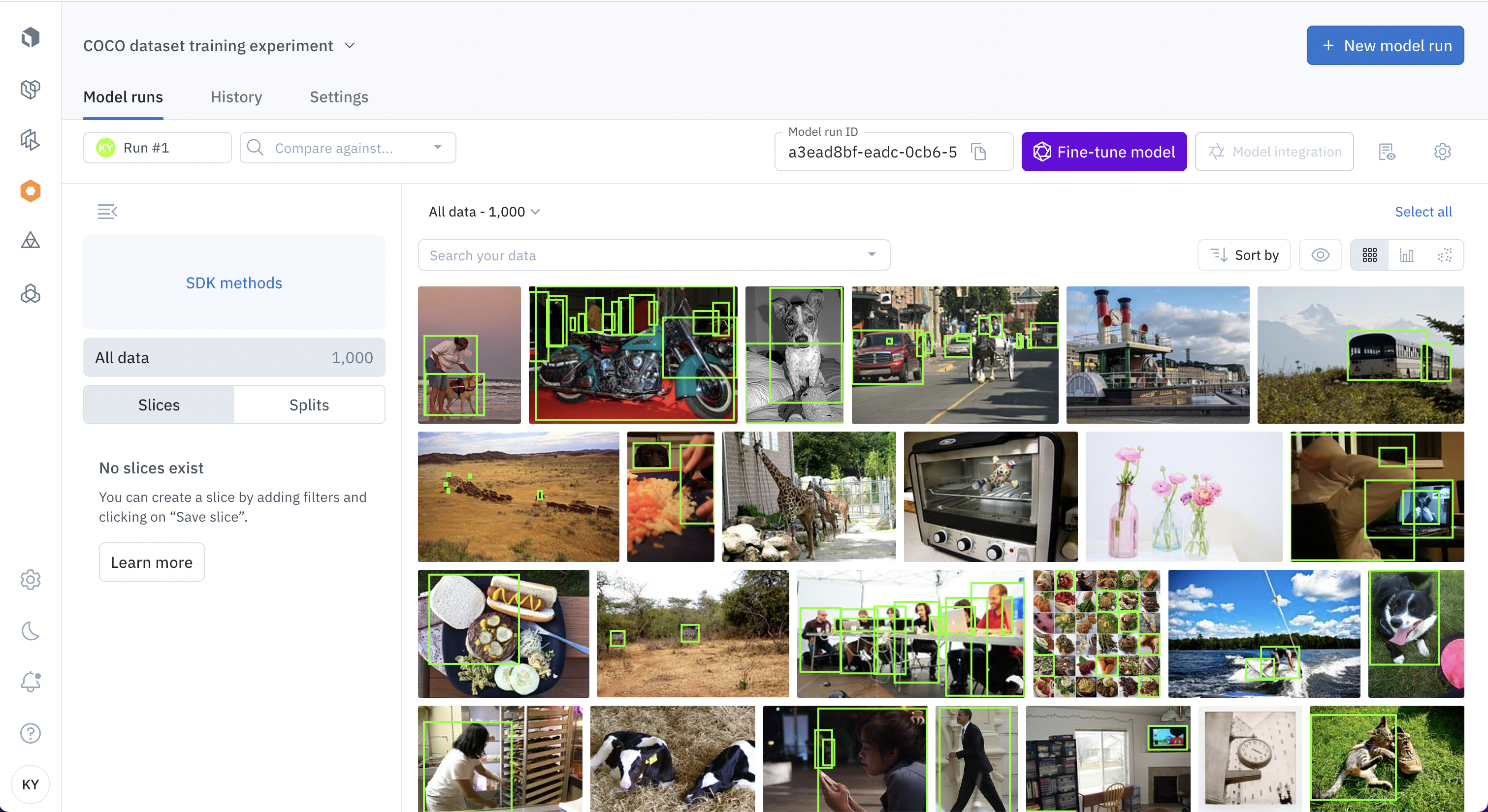
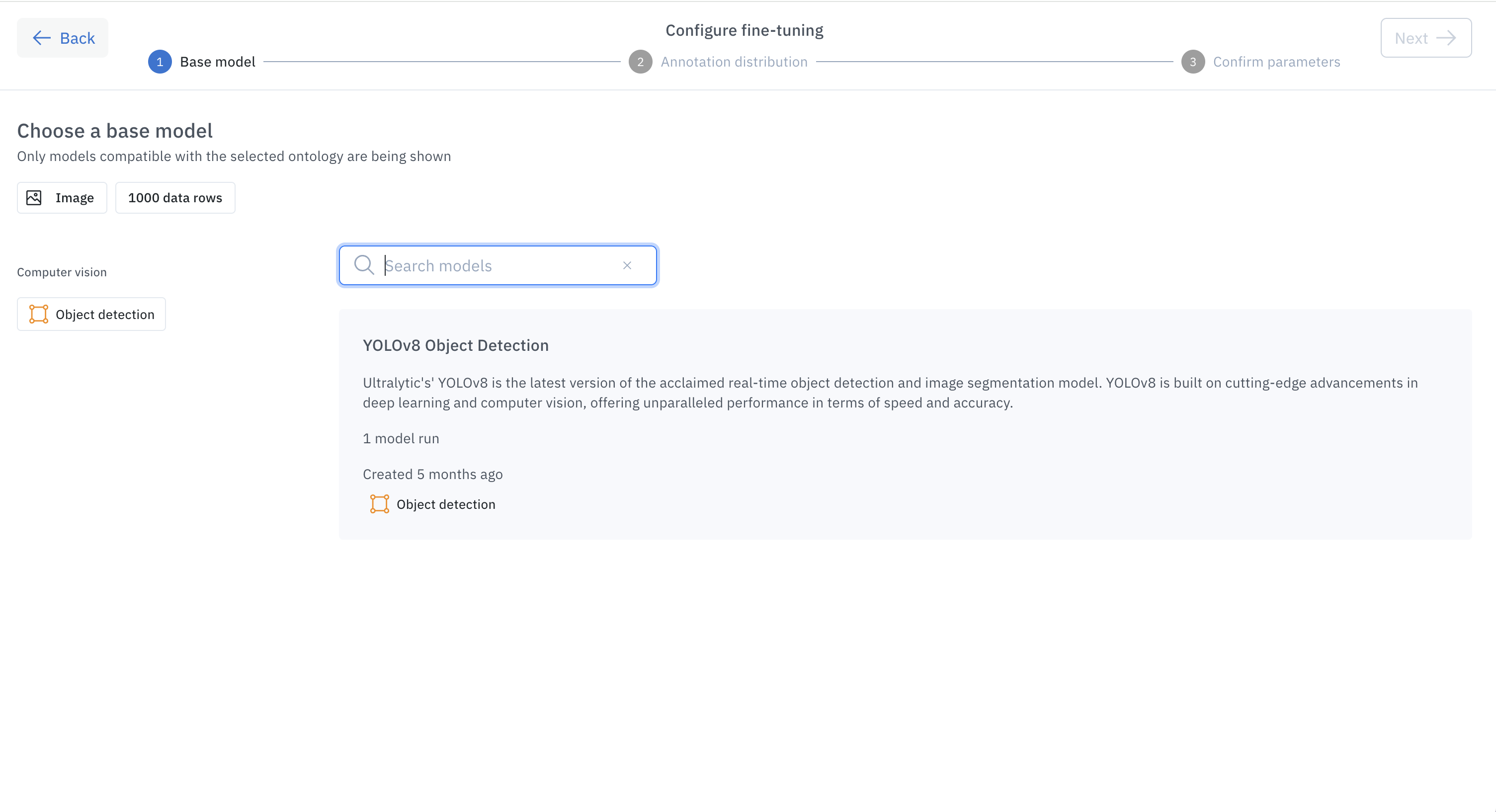
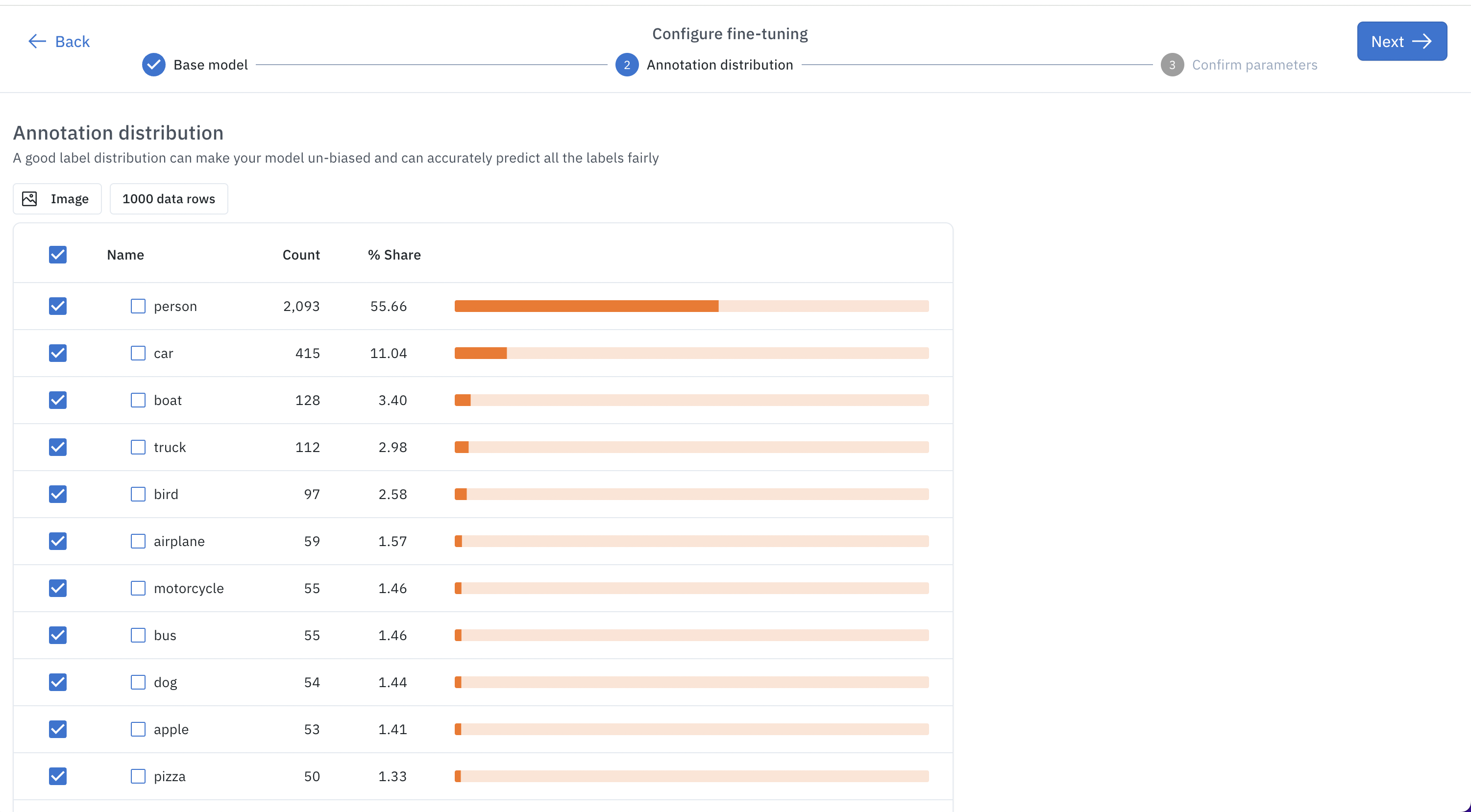
Use the tuned model
Once the model is fully trained, it will appear as a card in Model. You can also find a link to the trained model from the notification center. In Models, you can navigate to the Custom tab to see all available custom models you have fine-tuned.