- Quickly kick off low-code model development.
- Validate a hypothesis or business case with minimal ML effort.
- Train a model to accelerate data labeling.
Availability
The model training integration is currently available for pro and enterprise customers.How does the model training integration work?
The model training pipeline lets you run ETL jobs, train models, deploy models, and track model performance all from a single service.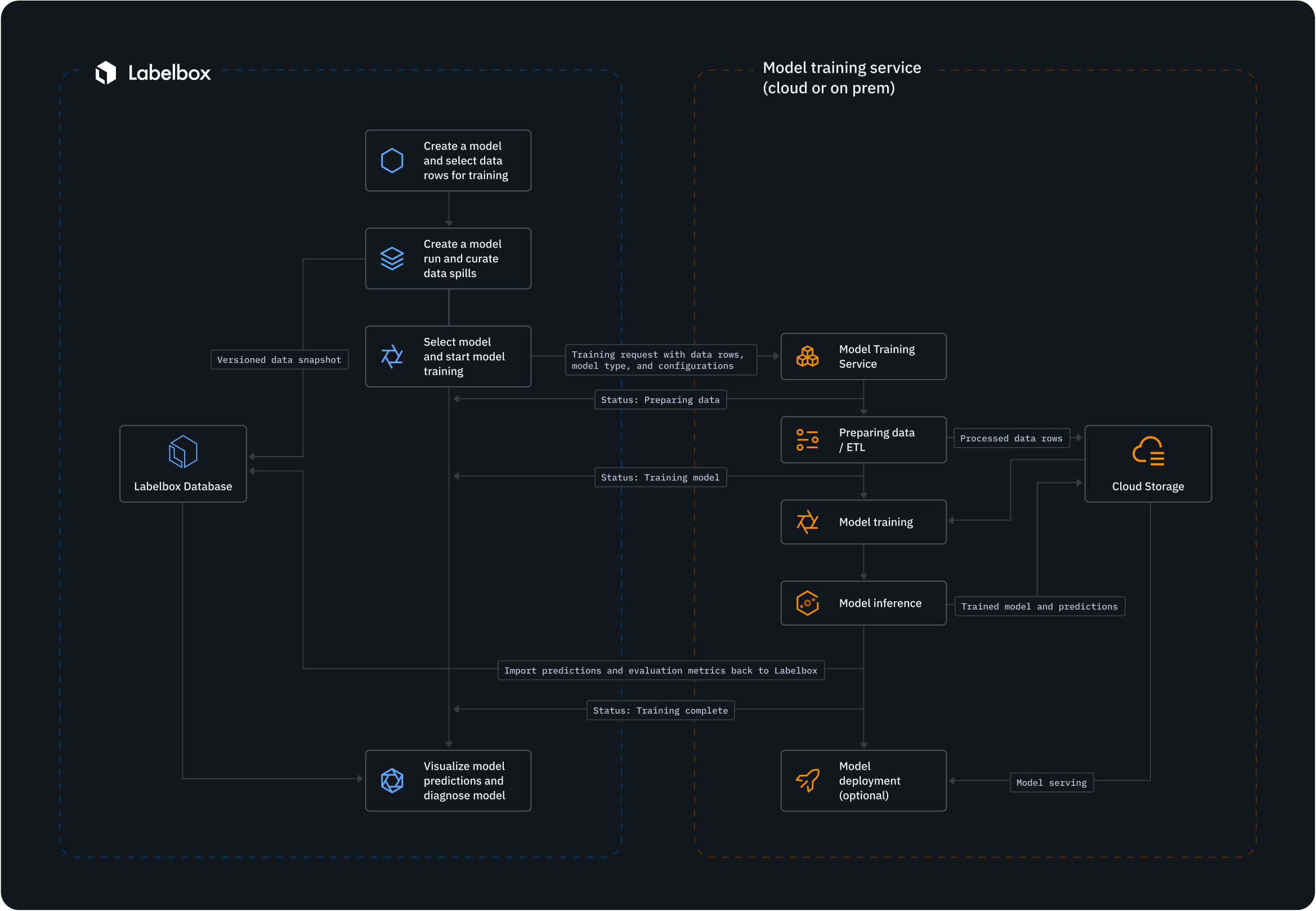
Reference architecture of the model training integration.
Which models are supported?
Labelbox provides you with two options for selecting a model architecture:- Select a model architecture from a list of supported reference models (see the table below).
- Set up your own custom model training pipeline hosted on your cloud provider. Visit our GitHub repository for a reference architecture code that you can modify and reuse.
Reference models
To help you jumpstart your model training, Labelbox provides you with a list of out-of-the-box machine learning models offered by Vertex AutoML. Below are the supported data types and tasks for model training with Labelbox.Custom model training
To use your own custom model for model training, visit our GitHub repository to check out the reference architecture implementation and add your custom model pipeline using the instructions in Customize a model training pipeline based on Labelbox reference implementationAutomatically connect to model error analysis tools
Model training is automatically connected to our model error analysis tools, allowing you to access powerful model evaluation tools without writing a single line of code. Once your model training is complete, you can instantly visualize your model’s evaluation and performance on each data row, find errors, and identify what to improve next.Open source models
To try out the Model product functionalities, you can navigate to the Model tab and select one of the open-source models.