Import text data
To learn how to text data to Labelbox, visit our docs on Importing text data.Supported annotation types
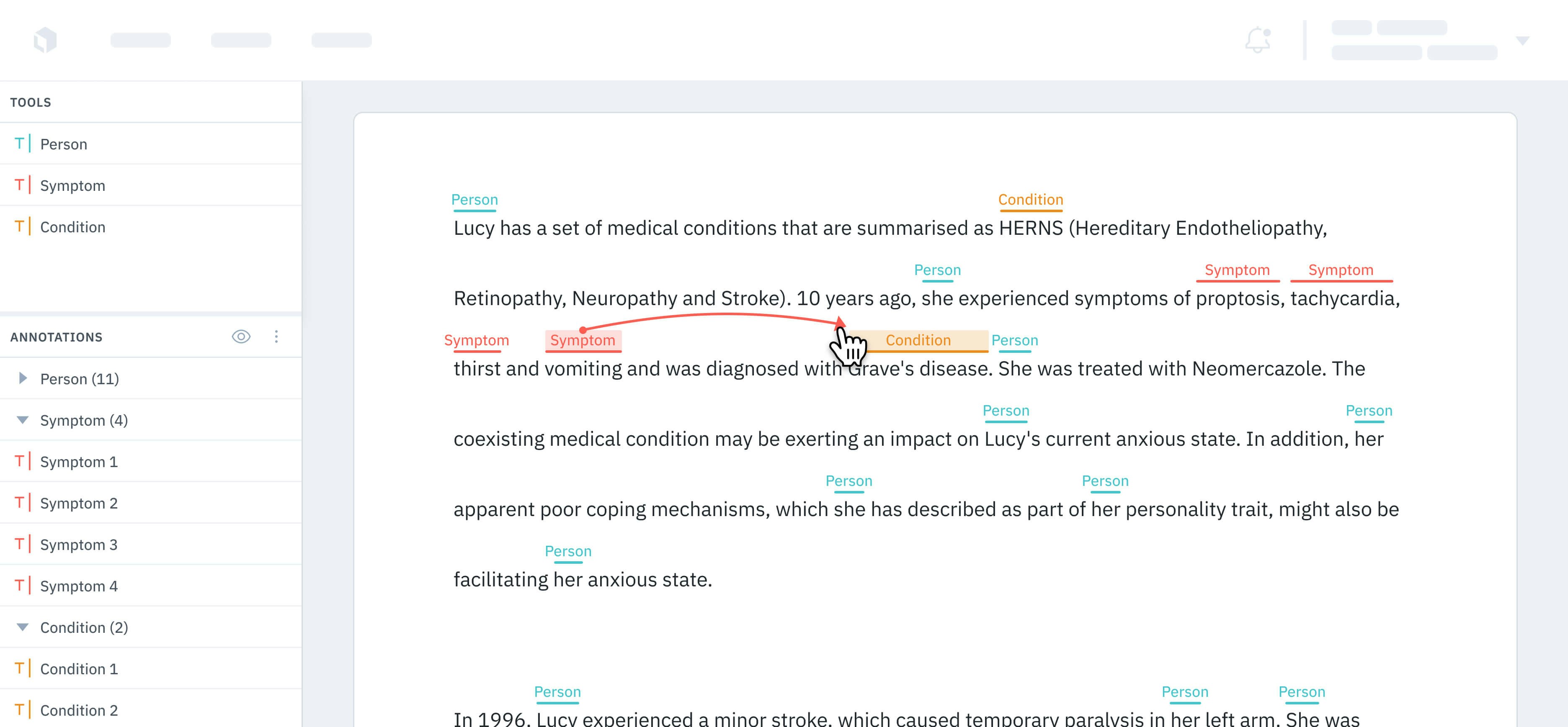
Below are all of the annotation types you may include in your ontology when you are labeling text data. Classification-type annotations can be applied at the global level and/or nested within an object-type annotation.Text entity
Create an entity by clicking the desired starting character and dragging to select a sequence of characters in the unstructured text.
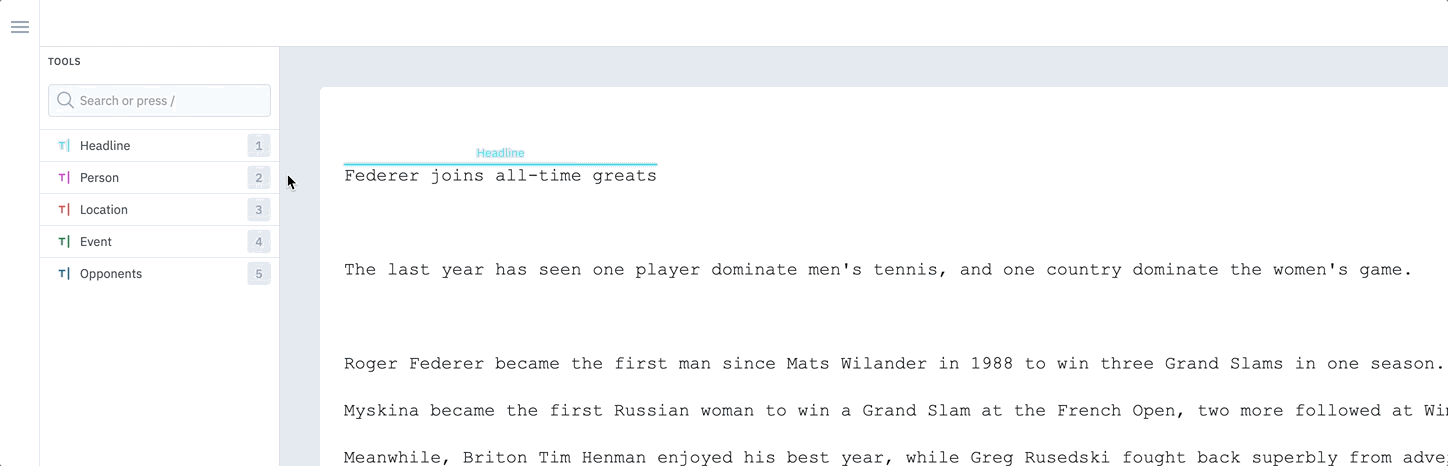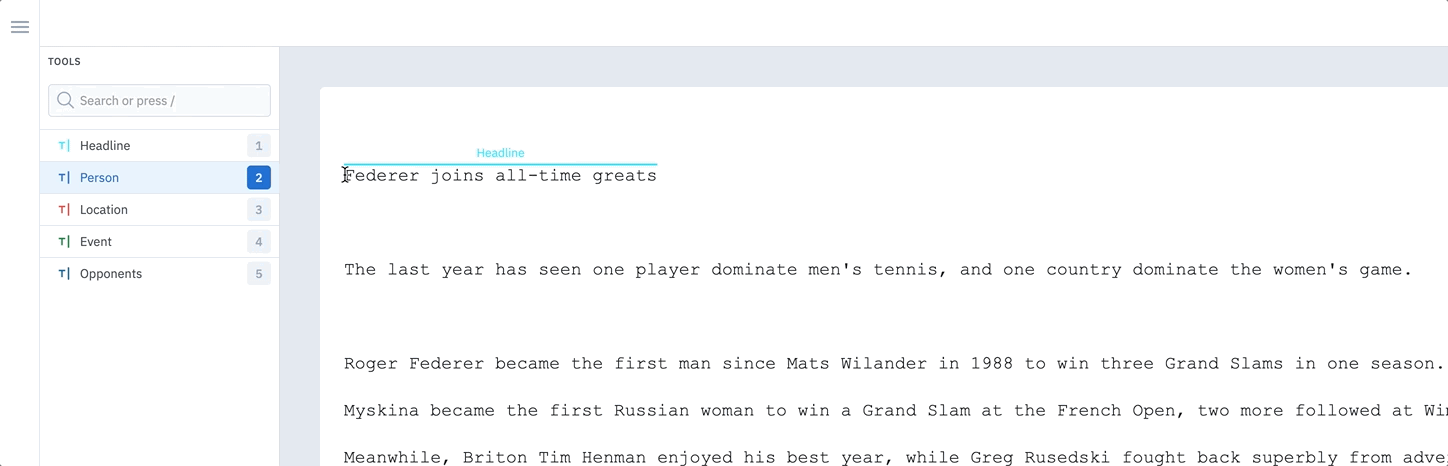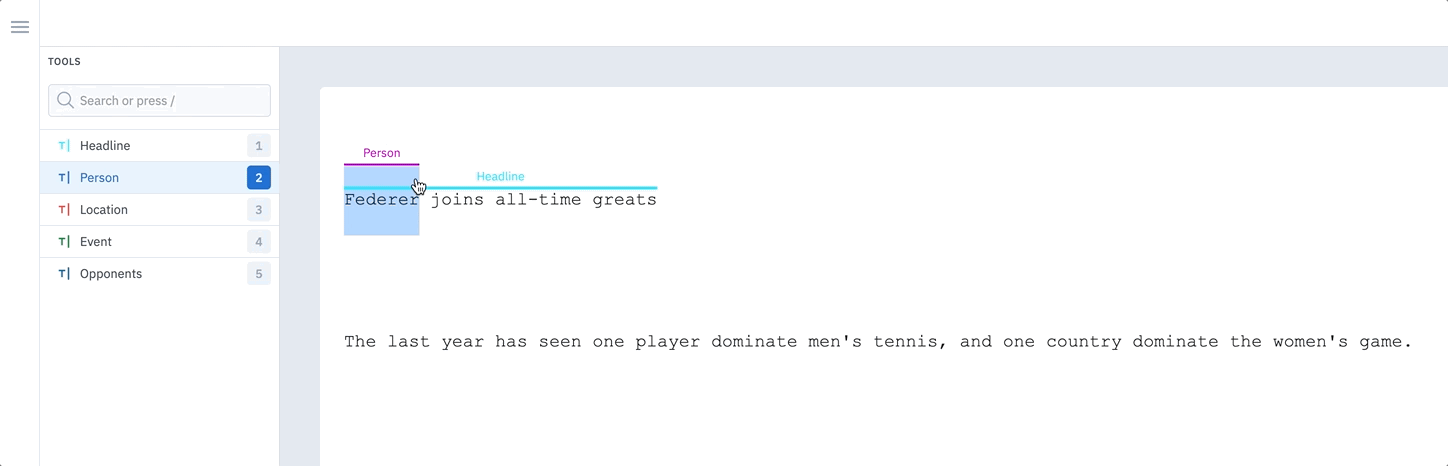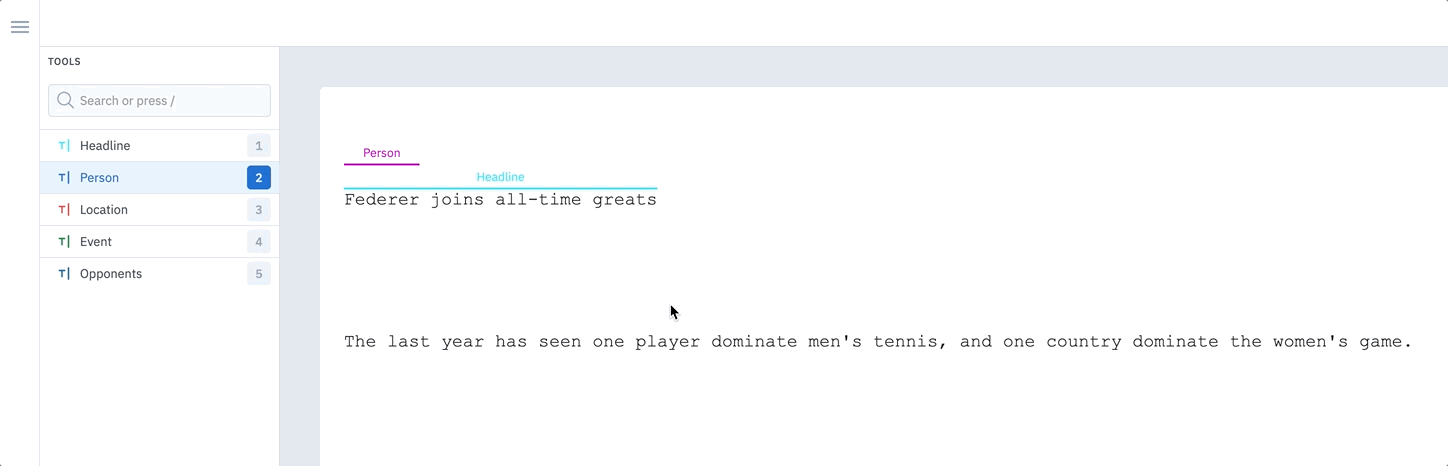
Full word selection
When labeling text, you can hover over and annotate full words with one click rather than dragging your cursor and labeling character by character. This feature allows for vastly more efficient labeling and decreases the likelihood of labeling errors. To toggle between Word and Character mode, click on the Settings icon in the text editor and select an option. You can also toggle between approaches using the hotkeysShift + W for Word mode and Shift + C for Character mode. The default setting for all users is Word mode.
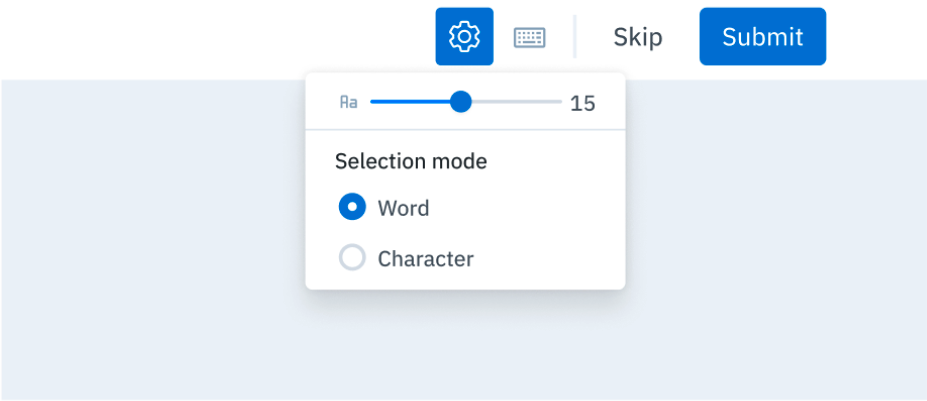
Toggle between word and character modes in the text editor.
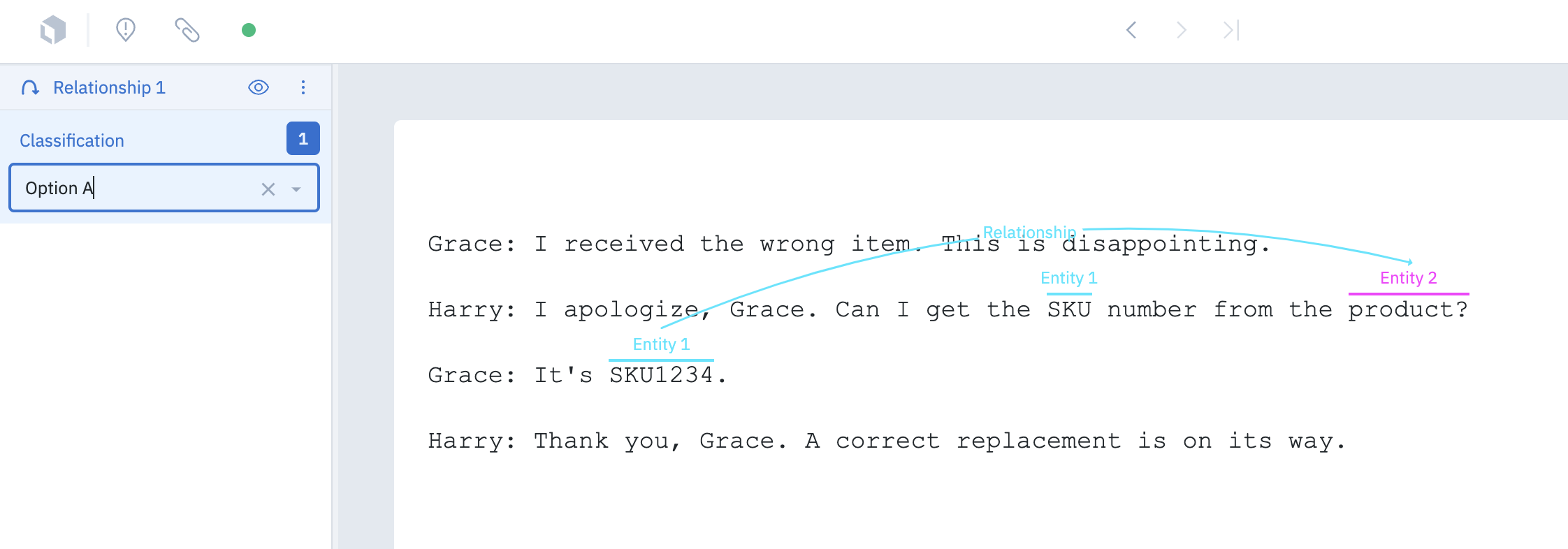
Relationship
With annotation relationships, you can create and define relationships between entity annotations in the text editor. You can then use these annotation relationships to consolidate labeling workflows and potentially reduce the number of language models needed. Follow these steps to create a relationship between two entity annotations:- In the editor, create two entity annotations.
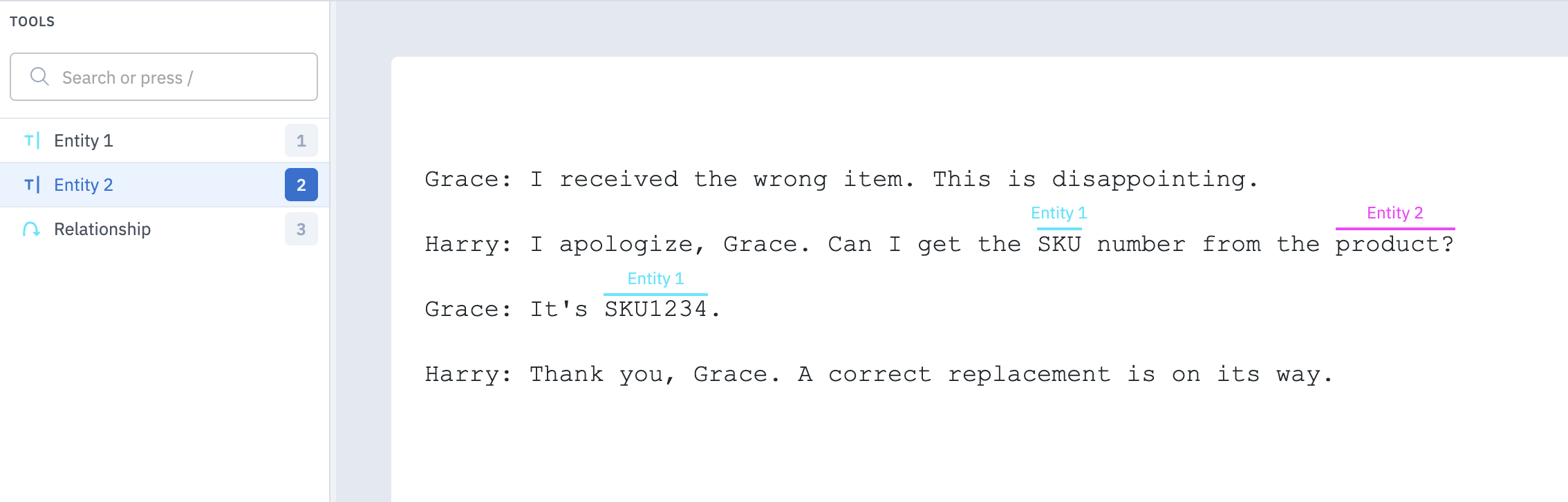
- Select the relationship annotation from the Tools menu, then click on one of the entity annotations. To create the relationship, move your cursor to another entity and click to create the relationship.
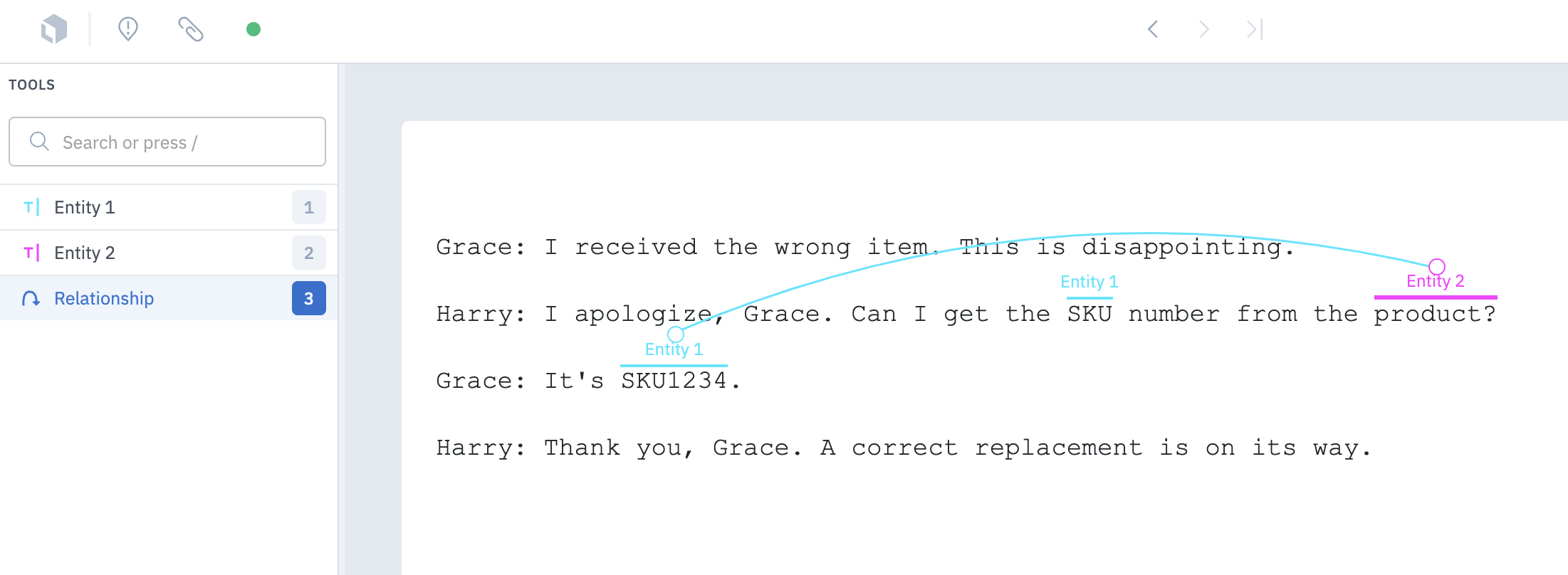
- Add an optional subclassification to the relationship.