- You have labeled at least 10 data rows without using model-assisted labeling
- You have imported at least 1 batch of labels as pre-labels using model-assisted labeling
- You have labeled at least 10 data rows with the model-assisted labeling pre-labels
How to interpret efficiency scores
Using our historical project data, we are able to bucket projects using labeling automation into several tiers. Those tiers along with their average time savings are shown in the table below.| Score Range | Category | Average time savings per label* |
|---|---|---|
| 76-100 | World Class | 65% |
| 51-75 | Good | 40% |
| 26-50 | Average | 10% |
| 1-25 | Needs Improvement | 0% |
- Note: These are average time savings over the projects in the score range. We cannot guarantee that all projects can achieve these levels of time savings within the score range due to a variety of factors like ontology complexity, asset type, and task difficulty.
Efficiency score calculation
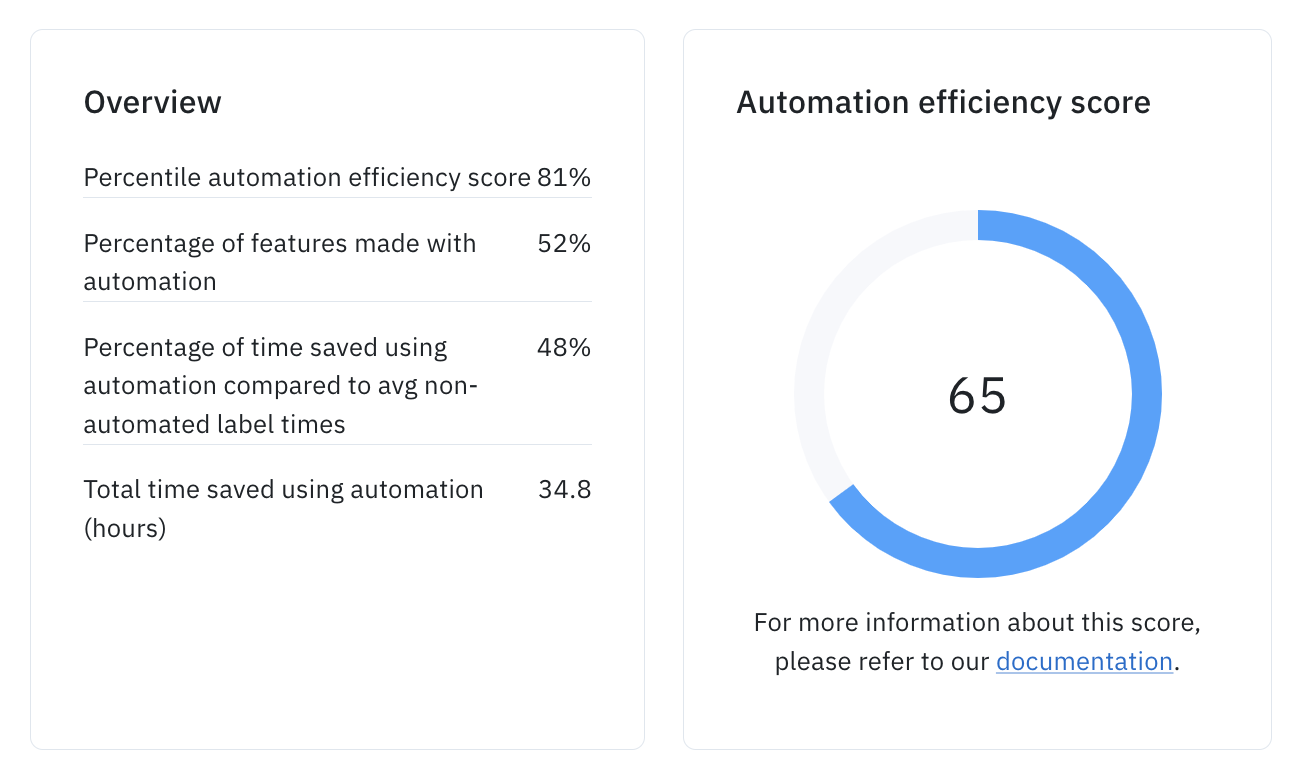
The automation efficiency score is a proprietary calculation but is heavily influenced by:- Percentage of features made with automation: This is the percentage of features in the project that were created with automation. This includes both unedited and edited features submitted that originally came through a model-assisted labeling import.
- Estimated percent time saved per label using automation: This is calculated by comparing the average time spent labeling using automation to the average time spent labeling without using automation.
- Total time savings saved across the project: This is the total time saved across the project’s lifetime. This has a very minimal impact on the score but projects with larger aggregate time savings will see slightly high scores.
Tips for improving efficiency score
In general, we have seen two ways at improving the automation efficiency score (and thus see an improvement in labeling efficiency): Increase the number of features made with automation The most obvious way to improve your labeling efficiency is to simplify and increase the number of features you are uploading as pre-labels. This can include importing pre-labels for more features in your ontology or importing more low-confidence predictions as pre-labels. Improve the model used to generate the pre-labels By focusing on iterating on your model, you will see a gradual improvement in your pre-labels over time as your model accuracy improves.