- Connect your data: Link the images, text, or other documents you need to label.
- Define your ontology: Create the specific classes and categories that your team will use for annotation.
- Assign your team: Invite and manage the labelers and reviewers who will work on the data.
- Monitor progress: Track the status of labeling, review, and rework tasks.
- Measure quality: Use tools like Consensus and Benchmark to ensure your labels are accurate and consistent.
Project overview
The Overview tab is your command center for a specific labeling project. It provides a comprehensive, at-a-glance summary of your project’s health, progress, and quality. Think of it as the first place you should look to understand what’s happening, identify potential issues, and ensure your project is on track to meet its goals.Project metrics
The Participation view is an embedded version of the Participation histogram from the Performance tab. Click on View details to open the chart in the Performance tab. The Pipeline view displays of all statuses in a project and a count of data rows in each status. It also provides a count of the issues. Status descriptions:Workflow tasks
From this section you can enter a specific step in the labeling workflow or quickly add an entirely new step.Analytics view
This section lists all the features in a project along with the count of annotations for each.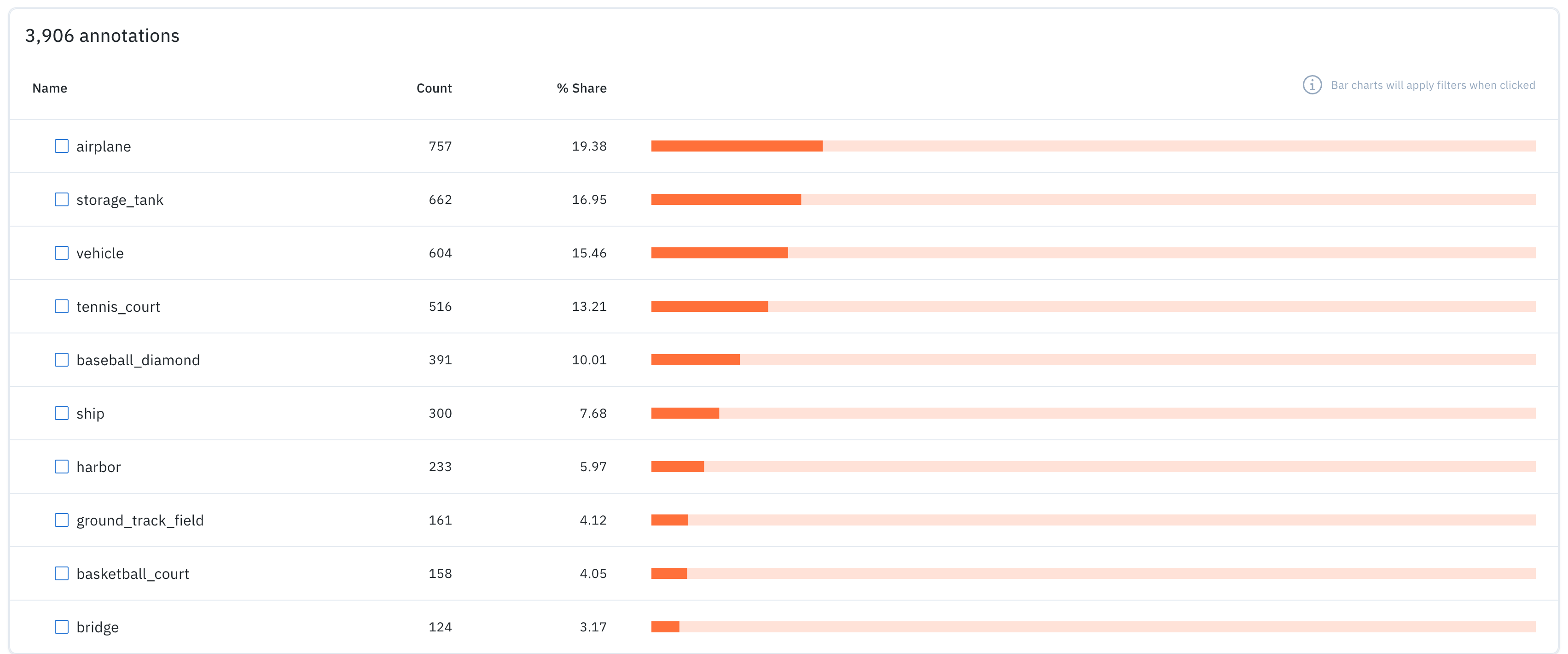
- Name of the feature.
- Count of data rows that contain the feature.
- % Share indicating the percentage of data rows that contain the feature.
- A horizontal bar chart that depicts the percent share. You can also click the bar to navigate to a filtered view of the data rows tab including only the data rows that contain the relevant feature.